https://qiita.com/woods0918/items/2d7b2421d8a8f1b6d724
@woods0918(VISITS Technologies株式会社)
VISITS Technologies Advent Calendar 2020 15日目は@woods0918が担当します。
私がプロダクトマネージャーを務めているideagramというサービスのバックエンドでは、REST APIからGraphQLへの移行が進んでいます。
初めてのGraphqlやGraphQL Playgroundを通してGraphQLの知識とクライアント側の操作は経験したのですが、GraphQLサーバーを実装した経験がなかったので、バックエンドエンジニアとの会話をスムーズにするために、挑戦してみようと思います。
今回は書き慣れているPythonで実装しますが、ideagramで採用している言語はRuby(WAF : Ruby on Rails)です。
コードはこちら
Pythonとライブラリのバージョン
python = "^3.8"
fastapi = "^0.62.0"
uvicorn = "^0.13.0"
SQLAlchemy = "^1.3.20"
graphene = "^2.1.8"
python-dotenv = "^0.15.0"
mysqlclient = "^2.0.2"
graphene-sqlalchemy = "^2.3.0"
ディレクトリ構成
# 説明に必要なファイルのみ抜粋
|--.env # データベース接続のためのパラメータを定義
|--app
|--__init__.py
|--cruds # データベースへ投げるクエリを定義
|--__init__.py
|--seeds.py
|--todos.py
|--users.py
|--database.py # データベースとの接続を定義
|--main.py # FastAPIのエンドポイント
|--models # SQLAlchemyで利用するクラスを定義
|--__init__.py
|--todos.py
|--users.py
|--schema # Grapheneで利用するQuery, Mutation, Schemaなどを定義
|--__init__.py
|--schema.py
|--todos.py
|--users.py
|--setting.py
database.py
import os
from contextlib import contextmanager
from sqlalchemy import create_engine, inspect
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import scoped_session, sessionmaker
from dotenv import load_dotenv
load_dotenv()
DB_USERNAME = os.getenv("DB_USERNAME")
DB_PASSWORD = os.getenv("DB_PASSWORD")
DB_HOSTNAME = os.getenv("DB_HOSTNAME")
DB_PORT = os.getenv("DB_PORT")
DB_NAME = os.getenv("DB_NAME")
DB_CHARSET = os.getenv("DB_CHARSET")
ENGINE = create_engine(
f"mysql://{DB_USERNAME}:{DB_PASSWORD}@{DB_HOSTNAME}:{DB_PORT}/{DB_NAME}?charset={DB_CHARSET}"
)
SESSION = scoped_session(
sessionmaker(autocommit=False, autoflush=False, bind=ENGINE, expire_on_commit=False)
)
class SelfBase(object):
def to_dict(self):
model = {}
for column in self.__table__.columns:
model[column.name] = str(getattr(self, column.name))
return model
BASE = declarative_base(cls=SelfBase)
BASE.query = SESSION.query_property()
@contextmanager
def session_scope():
session = SESSION()
try:
yield session
session.commit()
except:
session.rollback()
raise
finally:
session.close()
database.pyではデータベースとの接続周りを定義します。
DBのパラメーターは、dotenvのload_dotenvを利用して.envより読み取ります。
SESSIONはscoped_sessionとsessionmakerを利用して生成します。scoped_sessionを利用すると、何度もSession()を実行したとしても同じセッションが返却されます。
SelfBaseクラスは、(後ほど作成する)SQLAlchemyで利用するクラスを辞書型に変換するための基底クラスです。
sqlalchemyの基底クラスは、SelfBaseクラスを継承して生成します。
BASE.query = SESSION.query_property()をやっておくと、session.query(HogeClass).filter(HogeClass.col1 == "hoge").all()
をHogeClass.query.filter(HogeClass.col1 == "hoge").all()
のように書けるので、地味に便利です。
最後に、session_scopeはSQLAlchemyでのsessionの扱い方の記事を参考にさせていただきました。
with session_scope() as session:
# 何かしらのDB処理
という風に書いてあげると、いちいちcommitやcloseを書かなくて良くなるので便利だなと思いました。
models
modelsでは、SQLAlchemyで利用するクラスを定義します。Userクラスを例にします。
from sqlalchemy import Column
from sqlalchemy.dialects.mysql import INTEGER as Integer
from sqlalchemy.dialects.mysql import TEXT as Text
from app.database import BASE
class User(BASE):
__tablename__ = "users"
id = Column(Integer(unsigned=True), primary_key=True, unique=True, autoincrement=True)
name = Column(Text)
def __init__(self, name: str):
self.name = name
先ほど、database.pyで生成したsqlalchemyの基底クラスを継承して生成します。
__tablename__にDBの実際のテーブル名を定義します。
idとnameはテーブルのカラムです。sqlalchemyからデータ型をインポートして定義していきます。
MySQL独自の機能を利用する場合は、sqlalchemy.dialects.mysqlよりインポートしてください。
最後に、__init__で初期化処理を定義します。
cruds
seeds.py
seeds.pyでは、テーブルのCREATEとシードデータのINSERTを行います。
import sys
import pathlib
from datetime import datetime
current_dir = pathlib.Path(__file__).resolve().parent
sys.path.append( str(current_dir) + '/../../' )
from app.database import BASE, ENGINE, session_scope
from app.models.todos import Todo
from app.models.users import User
def generate_seed_data():
BASE.metadata.create_all(ENGINE)
users = [["太郎"], ["次郎"], ["花子"]]
todos = [
[1, "title1", "description1", datetime.now()],
[1, "title2", "description2", datetime.now()],
[2, "title3", "description3", datetime.now()],
[2, "title4", "description4", datetime.now()],
[3, "title5", "description5", datetime.now()],
[3, "title6", "description6", datetime.now()]
]
with session_scope() as session:
for user in users:
session.add(User(user[0]))
for todo in todos:
session.add(Todo(
user_id = todo[0],
title = todo[1],
description = todo[2],
deadline = todo[3]
))
if __name__ == "__main__":
generate_seed_data()
まず、BASE.metadata.create_all(ENGINE)でテーブルを生成します。
既存のテーブルから変更がない場合はスキップして作ってくれたり、「よしなに」CREATEを実行してくれるので、非常に便利です。
その後、Seedデータを生成し、with session_scope() as session:以降でINSERTを行います。
users.py
(後ほど)、QueryやMutationを行う際に利用するクエリを定義します。
from typing import Dict, Optional
from app.database import session_scope
from app.models.users import User
def insert_user(name: str) -> User:
user = User(name)
with session_scope() as session:
session.add(user)
session.flush()
return user
def fetch_user(id: Optional[int]=None, name: Optional[str]=None):
with session_scope() as session:
query = session.query(User)
if id:
query = query.filter(User.id == id)
if name:
query = query.filter(User.name == name)
return query.all()
名前の通りですが、insert_userではINSERTを、fetch_userではSELECTを行います。
schema
いよいよ、GraphQLの部分に入ります。
users.py
users.pyやtodos.pyでは、先ほどmodelsで生成したクラスに対応したGraphQL用のクラスを生成します。
import graphene
from graphene import relay
from graphene_sqlalchemy import SQLAlchemyObjectType
from app.models.users import User as UserModel
from app.cruds.users import insert_user
#-------------------------
# Query
#-------------------------
class User(SQLAlchemyObjectType):
class Meta:
model = UserModel
interface = (relay.Node, )
class UserConnections(relay.Connection):
class Meta:
node = User
#-------------------------
# Mutation
#-------------------------
class InsertUser(relay.ClientIDMutation):
class Input:
name = graphene.String(required=True)
user = graphene.Field(User)
@classmethod
def mutate_and_get_payload(cls, root, info, name):
user = insert_user(name)
return InsertUser(user)
Query
class UserはSQLAlchemyObjectTypeを継承して生成します。
さらに、model = UserModelでSQLAlchemyのクラスを紐づけることで、GraphQLとSQLAlchemyの間を上手く繋いでくれます。
詳細は、graphene-sqlalchemyのリポジトリを参照してください。
さらに、interface = (relay.Node, )やUserConnectionsを定義することで、簡単にRelay対応を行うことができます。
詳しくは、grapheneのrelayに関するドキュメントを参照してください。
Mutation
class InsertUserはrelay.ClientIDMutationを継承して生成します。InputでInsertUserを実行する際の引数を定義します。mutate_and_get_payloadでは、実際にDBにアクセスする処理を定義します。(先ほど、crudsのusersで定義したinsert_user関数を利用します。)
schema.py
schema.pyでは、QueryやMutationのRootとなる部分を定義します。
import graphene
from graphene import relay
from graphene_sqlalchemy import SQLAlchemyObjectType, SQLAlchemyConnectionField
from app.cruds.users import fetch_user
from app.cruds.todos import fetch_todo
from app.schema.users import User, UserConnections, InsertUser
from app.schema.todos import Todo, TodoConnections, InsertTodo
#-------------------------
# Query
#-------------------------
class Query(graphene.ObjectType):
node = relay.Node.Field()
user = graphene.Field(
lambda: graphene.List(User),
id=graphene.Int(required=False),
name=graphene.String(required=False)
)
todo = graphene.Field(
lambda: graphene.List(Todo),
id=graphene.Int(required=False),
user_id=graphene.Int(required=False),
title=graphene.String(required=False),
description=graphene.String(required=False),
deadline=graphene.DateTime(required=False)
)
all_users = SQLAlchemyConnectionField(UserConnections)
all_todos = SQLAlchemyConnectionField(TodoConnections, sort=None)
def resolve_user(self, info, id=None, name=None):
return fetch_user(id, name)
def resolve_todo(self, info, id=None, user_id=None, title=None, description=None, deadline=None):
return fetch_todo(id, user_id, title, description, deadline)
#-------------------------
# Mutation
#-------------------------
class Mutation(graphene.ObjectType):
insert_user = InsertUser.Field()
insert_todo = InsertTodo.Field()
#-------------------------
# Schema
#-------------------------
schema = graphene.Schema(query = Query, mutation=Mutation)
Query
node = relay.Node.Field()all_users = SQLAlchemyConnectionField(UserConnections)all_todos = SQLAlchemyConnectionField(TodoConnections, sort=None)
は、relayの規格に沿ったクエリを投げられるようにするためのものです。
userとresolve_user、todoとresolve_todoは対応するもので、マニュアルで定義したSELECT処理をGraphQLとして扱えるようにするためのものです。
Mutation
Mutationクラスにusers.pyやtodos.pyで生成したMutationクラスを紐づけていきます。
Schema
RootのQueryクラスとMutationクラスをSchemaに紐付けます。
main.py
最後に、FastAPIのエンドポイントを生成します。
import sys, pathlib, uvicorn, graphene
current_dir = pathlib.Path(__file__).resolve().parent
sys.path.append( str(current_dir) + '/../' )
from graphql.execution.executors.asyncio import AsyncioExecutor
from fastapi import FastAPI
from starlette.graphql import GraphQLApp
from app.schema.schema import schema
app = FastAPI()
app.add_route("/", GraphQLApp(schema=schema))
if __name__ == "__main__":
uvicorn.run("main:app", port=5000, reload=True, access_log=False)
FastAPI()でappインスタンスを生成し、/でGraphQLにアクセスできるようにroute設定を行います。
実行
以下のコマンドで起動できます。
python ./app/main.py
結果確認
今回は、GraphQL Playgroundを使って結果を確認していきます。
Schema
GraphQL Playground上では以下のように表示されます。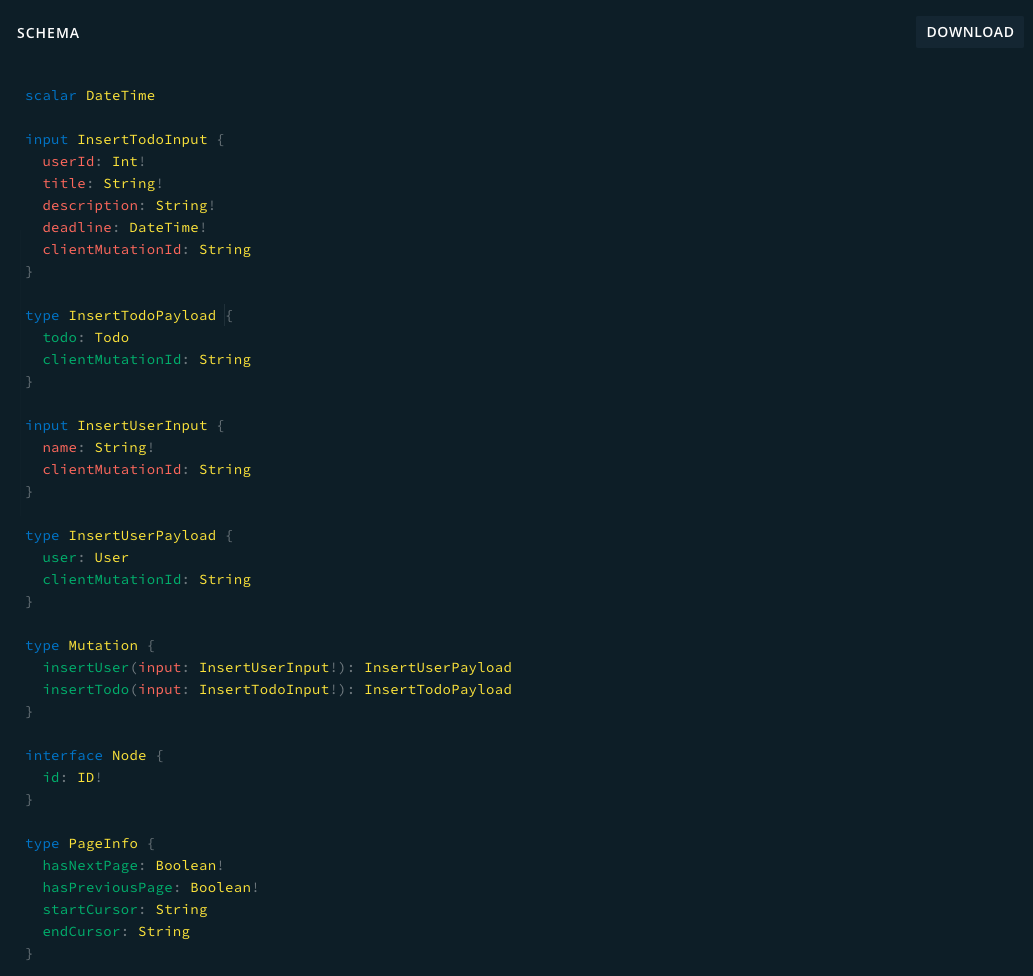
Schema全体は以下のようになります。
scalar DateTime
input InsertTodoInput {
userId: Int!
title: String!
description: String!
deadline: DateTime!
clientMutationId: String
}
type InsertTodoPayload {
todo: Todo
clientMutationId: String
}
input InsertUserInput {
name: String!
clientMutationId: String
}
type InsertUserPayload {
user: User
clientMutationId: String
}
type Mutation {
insertUser(input: InsertUserInput!): InsertUserPayload
insertTodo(input: InsertTodoInput!): InsertTodoPayload
}
# An object with an ID
interface Node {
# The ID of the object.
id: ID!
}
# The Relay compliant `PageInfo` type, containing data necessary to paginate this connection.
type PageInfo {
# When paginating forwards, are there more items?
hasNextPage: Boolean!
# When paginating backwards, are there more items?
hasPreviousPage: Boolean!
# When paginating backwards, the cursor to continue.
startCursor: String
# When paginating forwards, the cursor to continue.
endCursor: String
}
type Query {
# The ID of the object
node(id: ID!): Node
user(id: Int, name: String): [User]
# <graphene.types.scalars.String object at 0x111cd6ac0>
todo(id: Int, userId: Int, title: String, deadline: DateTime): [Todo]
allUsers(
sort: [UserSortEnum]
before: String
after: String
first: Int
last: Int
): UserConnectionsConnection
allTodos(
before: String
after: String
first: Int
last: Int
): TodoConnectionsConnection
}
type Todo {
id: ID!
userId: Int
title: String
description: String
finished: Boolean
deadline: DateTime
users: User
}
type TodoConnectionsConnection {
# Pagination data for this connection.
pageInfo: PageInfo!
# Contains the nodes in this connection.
edges: [TodoConnectionsEdge]!
}
# A Relay edge containing a `TodoConnections` and its cursor.
type TodoConnectionsEdge {
# The item at the end of the edge
node: Todo
# A cursor for use in pagination
cursor: String!
}
type User {
id: ID!
name: String
}
type UserConnectionsConnection {
# Pagination data for this connection.
pageInfo: PageInfo!
# Contains the nodes in this connection.
edges: [UserConnectionsEdge]!
}
# A Relay edge containing a `UserConnections` and its cursor.
type UserConnectionsEdge {
# The item at the end of the edge
node: User
# A cursor for use in pagination
cursor: String!
}
# An enumeration.
enum UserSortEnum {
ID_ASC
ID_DESC
NAME_ASC
NAME_DESC
}
PageInfoやinterface NodeなどはRelayに関わるところですね。
他にもクエリの結果を見ていきます。
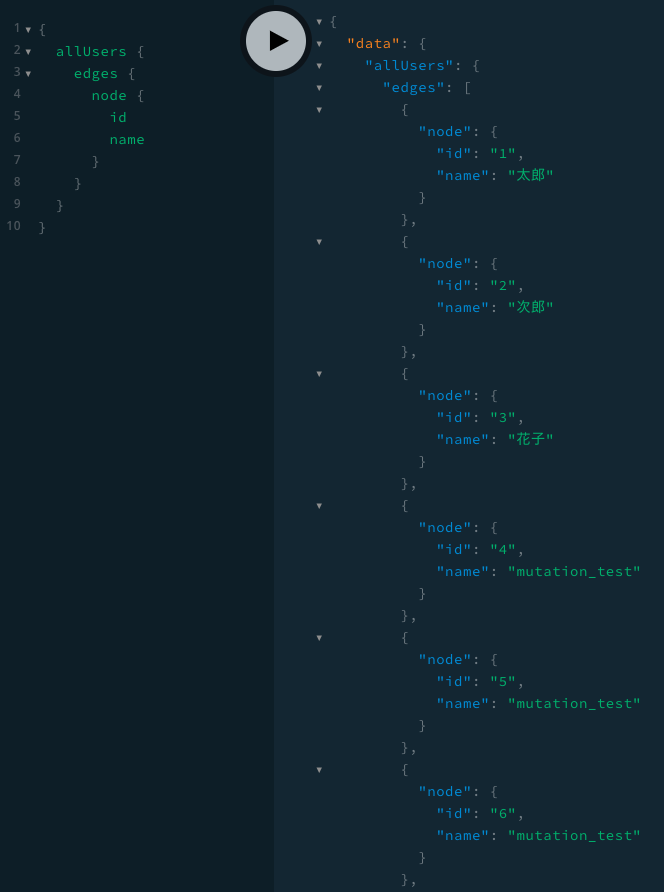
allUsers
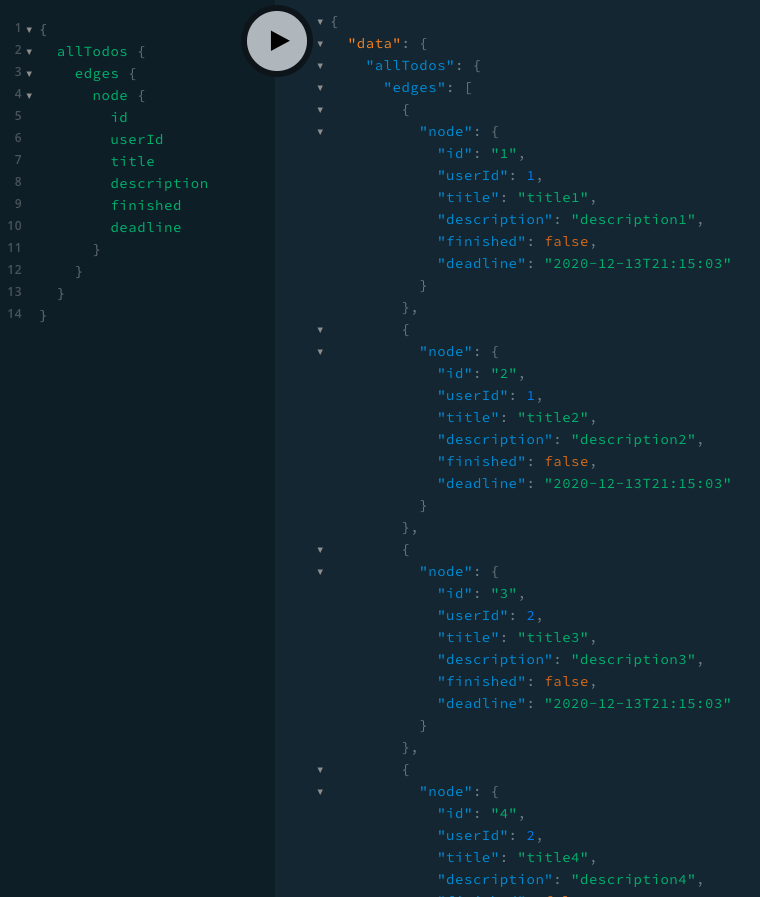
allTodos
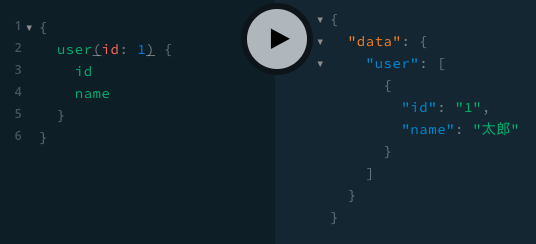
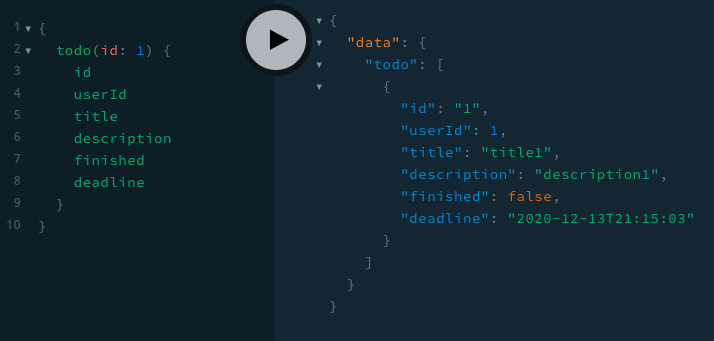
user(resolve_user)
todo(resolve_todo)
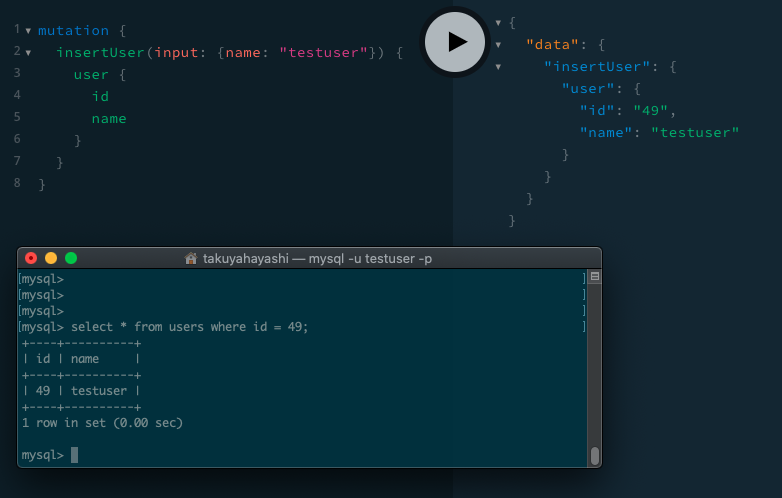
insertUser
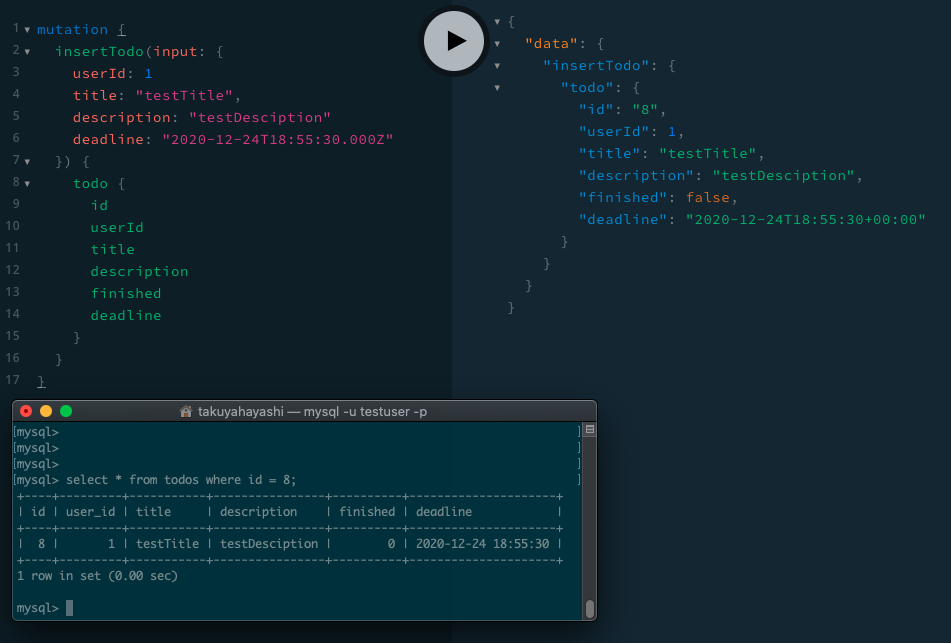
insertTodo
おわりに
はじめて、GrpahQLのサーバーサイドを構築しましたが、REST APIより難しいと感じるのは慣れていないからでしょうかね。
今度、同僚のエンジニアにコツを教えてもらおうと思います。
久しぶりにコードを書いたので、あまり綺麗に書けていなかったり理解が誤っている箇所があるかもしれませんが、その際はこそっとコメント欄で教えてもらえると幸いです。
明日は、ideagramのGraphQL化を1から進めた@ham0215による記事です、お楽しみに!
参考
公式
SQLAlchemy 1.3 Documentation
Graphene Documentaion
FastAPI Documentaion
graphene-sqlalchemyリポジトリ
記事
SQLAlchemyでのsessionの扱い方
PythonでGraphQLチュートリアル+α
FastAPI ディレクトリ設計
sqlalchemyのテーブル定義tips

0 件のコメント:
コメントを投稿