https://www.techno-edge.net/article/2023/07/17/1603.html?dicbo=v2-0IWyx8m


1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第3回目は、GoogleのDreamBooth改良、静止画1枚からアニメーション作成など5つの論文をまとめました。
生成AI論文ピックアップ
Google、キャラ学習手法のDreamBoothを高速・小型化 さらに1枚の学習元から可能にする「HyperDreamBooth」開発 DreamBoothより25倍高速
生成画像内に被写体を指定できる事後学習アプローチ「DreamBooth」にはサイズとスピードという欠点があります。サイズについては、Stable Diffusionでは1GB以上になることがあります。スピードの面では、DreamBoothモデルのトレーニングにStable Diffusionで約5分かかります。このため、作業の潜在的なインパクトが制限されます。
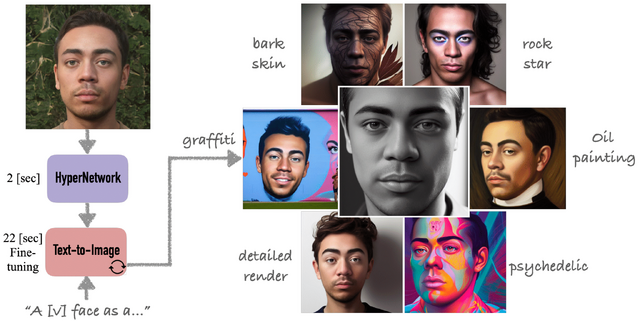
DreamBoothの開発元であるGoogle Researchは今回、DreamBoothの良さを維持しつつ高速化させた「HyperDreamBooth」を開発しました。この手法は、1枚の人物画像からパーソナライズされた重みの小さなセットを効率的に生成できるハイパーネットワークとなります。
これらの重みを拡散モデルに合成し、高速な微調整と組み合わせることで、HyperDreamBoothは、高い被写体詳細度で、様々な文脈とスタイルにおける人物の顔を生成できます。
多様な実験の結果、DreamBoothと同じ品質とスタイルの多様性を保ちながら、本手法はわずか1枚の参照画像を用いて、DreamBoothの25倍、Textual Inversionの125倍の速さで、顔のパーソナライズを約20秒で達成しました。また、通常のDreamBoothモデルよりも1万倍小さいモデルを生成することができました。
HyperDreamBooth: HyperNetworks for Fast Personalization of Text-to-Image Models
Nataniel Ruiz,Yuanzhen Li,Varun Jampani,Wei Wei,Tingbo Hou,Yael Pritch,Neal Wadhwa,Michael Rubinstein,Kfir Aberman
Project Page | Paper
画像1枚から動画を生成するAI「AnimateDiff」 DreamBoothやLoRAなどにも対応
一般的なText-to-Videoモデル(Stable Diffusionなど)では、オリジナルのText-to-Imageモデルに時間モデリングを組み込み、ビデオデータセットでモデルを微調整することが提案されています。しかし、パーソナライズされたText-to-Imageモデル(DreamBoothやLoRAなどを使って追加学習したモデル)では困難が伴います。なぜなら、ユーザーは通常、ハイパーパラメータの調整やパーソナライズされたビデオの収集、そして計算リソースに制限があるからです。
この研究では、どんなパーソナライズドされたText-to-Imageモデルに対してもアニメーション画像を生成できるようにするための手法「AnimateDiff」を提案します。AnimateDiffは、モデル固有のチューニング作業を必要とせず、静止画像1枚から外観の一貫性を保持した短い動画を生成します。
この手法では、ベースとなるText-to-Imageモデル(例えば、Stable Diffusion)を使用し、モーションモデリングモジュールを動画データセットで学習し、モーションプリオールを抽出します。この段階では、モーションモジュールのパラメータのみが更新され、ベースのText-to-Imageモデルの特徴空間は保持されます。
一度訓練されたモーションモジュールは データ収集やカスタマイズされたトレーニングのための更なる努力をすることなく、ベースとなったText-to-Imageモデルに対応する全てのパーソナライズされたText-to-Imageモデル(DreamBoothやLoRAなど)をアニメーション化します。
評価実験では、アニメキャラクターから写実的な画像まで、いくつかの代表的なパーソナライズされたText-to-Imageモデルで試されました。その結果、提案されたフレームワークは、外観の一貫性を保持しながら時間的に滑らかなアニメーションクリップを生成することに成功し、その有効性を実証しました。


AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Yaohui Wang, Yu Qiao, Dahua Lin, Bo Dai
Project Page | Paper
動画内の被写体を変えて別の動画を生成できるAI「Animate-A-Story」 テンセント含む研究者らが開発
既存のText-to-Videoモデルでは、ユーザーが動画内の被写体のレイアウトやモーションをほとんど制御することができません。この課題を解決するために、本研究では「Animate-A-Story」というアプローチを提案しています。この手法を使用すると、既存の動画内の被写体の位置や動きを維持したまま被写体だけをテキストプロンプトで変えた動画を生成することが可能です。
提案手法では、テキストに基づいて外部データベースから動画を検索し、検索された動画から構造を抽出して、Text-to-Video生成プロセスにガイダンス信号として提供します。そして、異なるビデオクリップ間で一貫性のあるキャラクター(ユーザーが提供したもの)を合成するために、提案手法に基づいてビデオキャラクターの再レンダリングを行います。
このシステムにより、動画内の被写体のレイアウトやモーションをある程度制御することができ、好みのキャラクターを組み込んだ一貫したストーリーテリングビデオを作成することができます。
例えば、自転車に乗って道の中央を走る子供の動画を選択した場合、テキストプロンプトに「テディベアが自転車に乗り、雪の森を通り過ぎる」と追加すると、雪の森の中央を自転車で走る熊の動画が出力されます。

Animate-A-Story: Storytelling with Retrieval-Augmented Video Generation
Yingqing He, Menghan Xia, Haoxin Chen, Xiaodong Cun, Yuan Gong, Jinbo Xing, Yong Zhang, Xintao Wang, Chao Weng, Ying Shan, Qifeng Chen
Project Page | Paper | GitHub
テキスト、画像、動画を同時に処理し生成する大規模マルチモーダルモデル「Emu」
1つの機械学習モデルでテキスト、画像、動画など複数のモダリティを組み合わせて理解する大規模マルチモーダルモデル(Large Multimodal Model: LMM)が研究されています。しかし、これらのLMMは主に画像とテキストのペアやドキュメントに対して学習されることがほとんどであり、マルチモーダルデータのスケーラブルな供給源である動画像データは見過ごされているという課題があります。
この研究では、ビデオと画像データから学習するTransformerベースの大規模マルチモーダルモデル「Emu」を提案します。Emuは、視覚とテキストの両方のトークンを含むデータに対して自己回帰目的で学習され、画像に対するキャプション付けや画像や動画への質問応答、テキストから画像への生成などの多様なマルチモーダルタスクを遂行できる能力を持っています。
さらに、Emuは新たな能力を備えており、例えばコンテキスト内のテキストと画像の生成や画像のブレンドなどのタスクをこなすことができ、汎用的なインタフェースとして機能します。
ゼロショット/少数ショットの幅広いタスクにおいて、Emuは最先端の大規模マルチモーダルモデルと比較して優れた性能を発揮しています。また、命令チューニングによるマルチモーダルアシスタントなどの拡張機能も実証されています。

Generative Pretraining in Multimodality
Quan Sun, Qiying Yu, Yufeng Cui, Fan Zhang, Xiaosong Zhang, Yueze Wang, Hongcheng Gao, Jingjing Liu, Tiejun Huang, Xinlong Wang
Paper | GitHub | Demo
2つの点で画像をドラッグ編集できる新モデル「FreeDrag」
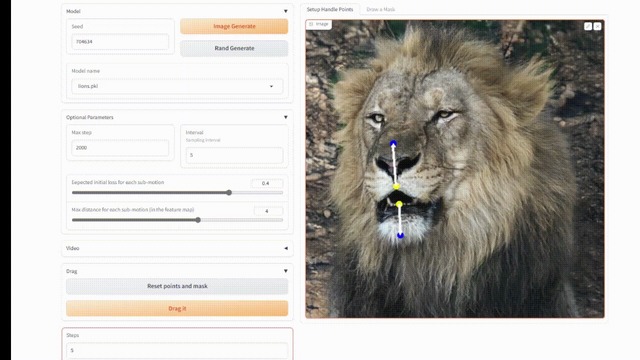
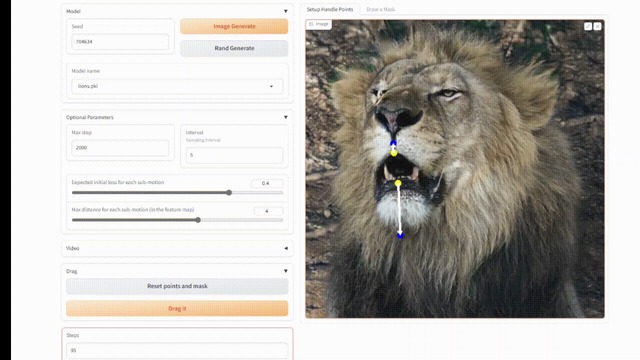
ドラッグ編集と呼ばれるポイントベースのインタラクティブな編集機能が注目を集めている「DragGAN」は、精密な画像編集の領域で大きな貢献をしています。DragGANは、2つの段階で編集が行われます。
第一段階は、ハンドル点(赤い点および黄色い点)をターゲットポイント(青い点)に移動させるよう指示するステップです。第二段階は、移動したハンドル点の位置を一貫して追跡する点追跡ステップです。これらのアプローチにより、ユーザーは画像上のハンドルポイントとターゲットポイントの2点のペアを指定することで、編集プロセスを正確に制御することができます。
しかし、DragGANにはいくつかの欠点があります。1つはミストラッキングであり、目的のハンドルポイントを効果的にトラッキングすることが困難な場合があります。もう1つの問題は曖昧なトラッキングで、トラッキングされたポイントがハンドルポイントに似ている他の領域内に位置することです。
この研究では、これらの問題を解決するためのドラッグ編集モデル「FreeDrag」を提案します。FreeDragは、DragGANのポイント指向の手法の中で、点追跡の負担を軽減するために特徴指向のアプローチを採用しています。また、ミストラッキングの問題に対処するために、各ハンドル点に対してテンプレート特徴(動作中のハンドルポイントの特徴を記録する概念)を保持し、反復プロセス中の動きを監視する手法を導入しています。
幅広い実験により、FreeDragの点ベースの画像編集における優位性と安定性が証明され、柔軟で正確な画像編集の分野で重要な進歩が示されました。

FreeDrag: Point Tracking is Not You Need for Interactive Point-based Image Editing
Pengyang Ling, Lin Chen, Pan Zhang, Huaian Chen, Yi Jin
Project Page | Paper | GitHub
0 件のコメント:
コメントを投稿