シェアしました。
Click here for English version.
2018/07/26

初めまして! インターンの長瀬です。普段はWebフロントエンド関連の業務をしています。
今回は、私がApollo GraphQLを使ってWebサービスを開発してみて感じたこと・考えたことを共有します。前半では開発での知見を活かし、GraphQL APIをRESTful APIと比較しながら紹介していきますので、GraphQLなんて使ったことがないよ! という方もお楽しみいただけるかと思います。
tl;dr
- WebサービスをApollo GraphQLで開発した
- サービスにおいて、特に複雑なグラフ構造のデータモデル等はなかったが、型定義の自動生成や単一エンドポイントなどの点でGraphQLを使う意義があったと感じた
- Apollo GraphQLはブラウザ拡張やapollo-codegenなどの開発支援も充実しており、快適に開発ができた
GraphQL, Apollo GraphQLについて
GraphQL, Apollo GraphQLについてすでにご存じの方は読み飛ばしていただいて結構です。
GraphQLについて
そもそも、GraphQLはWeb APIのためのクエリ言語です。RESTfulなAPIが抱えがちな以下の課題を解決できます。
- エンドポイントやURLのクエリパラメータが煩雑になる
- 目的のリソース以外の余計なデータがついてくることがある
- リソースをフェッチするために必要なリクエスト数が多くなりがち
エンドポイントやURLのクエリパラメータが煩雑になる
たとえばレスポンシブ対応の一環としてモバイルとPCで別サイズの画像を返したい時や、件数の多いデータをページネーション形式で返したい場合など、場合分けが必要になってくるにつれてURLのクエリパラメータが煩雑になってしまいます。
また、APIのエンドポイントの構造もAPIが大規模化するにつれて複雑になっていきます。
対して、GraphQLのエンドポイントは単一であり、またURLのクエリパラメータは使わずにGraphQLの
例として、ブログサービスにおいて特定の投稿以降に投稿された投稿を20件分取得したい場合には、以下のような
Query内に記述します。QueryはGraphQL APIが提供しているデータのうち何がほしいかを簡潔に記述したもので、HTTPリクエストのbodyに乗せて送ります。例として、ブログサービスにおいて特定の投稿以降に投稿された投稿を20件分取得したい場合には、以下のような
Queryを記述します。{
latest(after: "ID", count: 20) {
cursors {
after
},
posts {
title
thumbnailUrl
description
}
}
}
QueryはURLのクエリパラメータやセッション等を使うより可読性や表現力が高く、静的な型付けがされるため(afterはString, countならInt)、エディタでの自動補完やコード・ドキュメントの自動生成などの恩恵を受けることができます。RESTfulなAPIでもopenapi-generator(swagger-codegen)などを使うことで同様なことが可能ですが、GraphQL APIの場合はGraphiQLというAPIのテストツールやエディタにおいてQuery自体に対して補完が効くため非常に便利です。また、GraphQL APIサーバはIntrospectionという機構を持っており、cliツールなどを利用してすでに動作しているAPIサーバからAvailableなQueryや型などの情報を吸い出してファイルにダンプできます。このファイルをコードの自動生成・補完に利用するというしくみです。
サーバでこのクエリをどのように処理するかというと、クエリで指定されるフィールドごとに
resolverという関数を定義し、対応するデータをDBなどのデータストア等から取得して返すようにします。resolverの書式は以下の通りです。fieldName(obj, args, context, info) { result }
見ての通り、
resolverは最大4つの引数を取ります。objには、指定したフィールドの親フィールドのデータが含まれています。親フィールドが存在しない場合(ルートのフィールドの場合)には、設定値が返されます。argsには、クエリで渡した引数(先の例のafter,countに該当)が含まれています。contextには、すべてのresolverで引き回して使いたいような、セッション・ヘッダ・APIエンドポイントのURLなどの情報が含まれます。たとえば「ログイン済みのユーザーのみがデータへアクセスできるようにしたい場合」や、先程挙げた「モバイルとPCで別サイズの画像を返したい場合({device: 'pc'}などとしてデバイスタイプの情報を指定する場合)」などで有用です。infoでは、そのフィールドの名前やパス(ルートからそのフィードを指定するまでの道筋)、親フィールドの型などのメタデータが含まれています。
また、
Queryと同様にして、GraphQL APIが提供しているデータに変更を加えたい場合にはMutationを、データに対するMutationを監視して常に最新の状態を維持したい場合にはSubscriptionを書くことができます。GraphQL APIはこれらのQuery, Mutation, Subscriptionの3つの操作から成り立っています。目的のリソース以外の余計なデータがついてくることがある
ブログサービスの例で、あるユーザーのidからユーザー名を取得したい場合、RESTfulなAPIでは
/users/:idや/users?id='id'に対してリクエストをし、以下のようなレスポンスを得るはずです。{
name: "haruka",
id: "19900204",
posts: [],
subscriptions: [],
subscribedBy: [],
thumbnailUrl: []
}
ほしいデータはユーザー名のみなのですが、購読・被購読者や過去の投稿の一覧までが返されてしまいます。アプリケーションのアクティブユーザー数が増えてくると、クライアント<->APIサーバおよびAPIサーバ<->データストアの通信回数が大きく増えて問題になりかねません。そこで、GraphQLでは以下のような
Queryでリクエストします。{
user(id: "19900204") {
name
}
}
必要なフィールドのみを指定するため、余分なデータが取得され返されることはありません。
{
name: "haruka"
}
リソースをフェッチするために必要なリクエスト数が多くなりがち
先程のレスポンスが、以下のように購読者一覧を含んでいたとします。
{
name: "haruka",
id: "19900204",
posts: [],
subscriptions: [
"/users?id=19910917",
"/users?id=19861028",
"/users?id=19851025"
],
subscribedBy: [],
thumbnailUrl: []
}
全購読者のユーザオブジェクトを取得しようとすると、計4回のラウンドトリップが発生します。先程の例で紹介したように、GraphQL APIでは必要なフィールドだけを指定して1度の通信ですべてのデータを取得するため、通信コストが大きく削減できます。
また、
facebook/dataloaderなどと組み合わせることで、深くネストしたクエリについて、キャッシュやバッチ処理を利用し効率的にデータストアからデータをフェッチできます。こちらはAPI<->DBについての話題であり、GraphQL APIに限らずさまざまなシーンで利用可能です。Apolloとは
Apollo vs Relay
ApolloとはGraphQL APIのクライアントライブラリの1つです。ほかにはGraphQLの開発元であるFacebookによるRelayが有名ですが、対応しているクライアントや開発ツールの充実度からApolloに分があると考え、こちらを採用しました。
| Apollo | Relay | |
|---|---|---|
| 対応クライアント | React.js, Vue.js, Angular, Swift, Java, etc… | React.js |
| 開発ツールの充実度 | launchpad, engine, codegen, ブラウザ拡張等盛りたくさん | playground環境 |
| ドキュメントの充実度 | 充実(動画、 ブログ、 Webサイト等) | 比較的充実(Webサイトのみ) |
| ローカルステートの管理 | apollo-link-stateを利用可能 | Redux, MobX, etc.. |
Apolloはモックサーバを手早く簡単に作成・公開できるApollo Launchpadや、APIサーバの監視・解析ツールであるApollo Engine、そしてAPIサーバを解析してクライアント毎にコードを自動生成するapollo-codegen(apollo-cliというリポジトリ名に変わりました)といった充実した開発ツールが用意されています。
apollo-link-stateによるローカルステートの管理
Apolloが注目されている理由の1つとして、公式が「
apollo-link-stateを利用してローカルステートを管理することで、ReduxやMobXといった他の状態管理の機構を使わなくて済む」ことを謳っている点があります。apollo-link-stateにより、single source of truthなデータストアでリモート(API)のデータとアプリケーションの状態の両方を管理することが可能だということです。
ブログサービスの例で考えてみます。ユーザーが過去の投稿の一覧を複数選択し、まとめて削除できるような機能を作りたいとしましょう。
apollo-link-stateを使うことで、過去の投稿一覧のQueryは以下のように書けます。query allPosts($userId: ID!) {
allPosts(userId: $userId) {
id
content
selected @client
author {
id
name
thumbnailUrl
}
}
}
@clientというディレクティブをこのように使うことで、APIではなくブラウザのインメモリキャッシュからデータをフェッチできます。同様に先ほど紹介したmutationについても、DB等のリモートのデータではなく、キャッシュのデータに変更を加えるようにできます。mutation selectPost($postId: ID!) {
selectPost(postId: $postId) @client {
selected
}
}
このようにして、ローカルステートとリモートのデータを共通のインタフェース(=GraphQL)で管理し、single source of truthを実現しています。
しかしながら、実際のユースケースではほかのRESTfulなAPIと組み合わせて使うケースがほとんどかと思います。その際は
apollo-link-restというパッケージを利用できます。こちらはapollo-link-stateとは異なりunder active developmentな状態ですが、以下のようにしてRESTfulなAPIに対してQuery, Mutationを発行できます。query allPosts {
allPosts @rest(type: "Post", path: "/posts") {
id
content
}
}
mutation publishPost(
$someApiWithACustomBodyKey: PublishablePostInput!
) {
publishedPost: publish(input: "19900204", body: $someApiWithACustomBodyKey)
@rest(
type: "Post"
path: "/posts/{args.input}/new"
method: "POST"
bodyKey: "body"
) {
id
title
}
}
実際に開発してみて
開発の流れ
実際にApollo GraphQLを使ってWebサービスをゼロから作ってみました。大まかな開発の流れは以下のようになりました。
- Node.js(with TypeScript, graphql-yoga)でAPIサーバを書く
- graphql-yoga: Apollo, Relayに対応したNode.js向けのGraphQL APIフレームワーク Expressのミドルウェアを利用可能
- GraphQLでAPIのスキーマを書く
- 2のスキーマから、gql2tsというツールでTypeScriptの型定義を生成する
- 3の型定義を利用して、resolverを書いていく
- GraphiQLでAPIをテストする
- angular-cliでアプリケーション側(フロントエンド)のスケルトンを作成する
- APIに対するクエリをGraphQLで書く
- apollo-cliを使って、APIサーバのインストロペクション結果と7のクエリから、フロントエンドで使うTypeScriptの型定義を自動生成する
- 8の型定義を使ってフロントエンドのロジック部分を書いていく(apollo-angularを利用)
Apollo GraphQLのよかったところ
今回の案件ではフロントエンドとサーバサイドの両方でTypeScriptを利用したのですが、どちらの環境でもスキーマから自動生成された型定義を利用してスムーズに開発を進めることができました。またフロントエンドではフレームワークにAngularを利用しましたが、
QueryのレスポンスはObservableで返されるため、違和感なく使うことができました。
さらに、ブラウザ拡張のApollo Client Developer Toolsも便利でした。Developer Toolsには以下の機能が備わっています。
– GraphiQLをその場で実行する(本来であればAPIサーバと別のポートでGraphiQLサーバを立ち上げて、ブラウザでそこにアクセスして利用します)
– JavaScriptから発行されたクエリのログの確認、クエリの編集・再発行
–
– GraphiQLをその場で実行する(本来であればAPIサーバと別のポートでGraphiQLサーバを立ち上げて、ブラウザでそこにアクセスして利用します)
– JavaScriptから発行されたクエリのログの確認、クエリの編集・再発行
–
apollo-link-stateでキャッシュに書き込んだ値の確認(apolloはクエリのレスポンスを勝手にキャッシュしてくれるのですが、その内容も確認できます)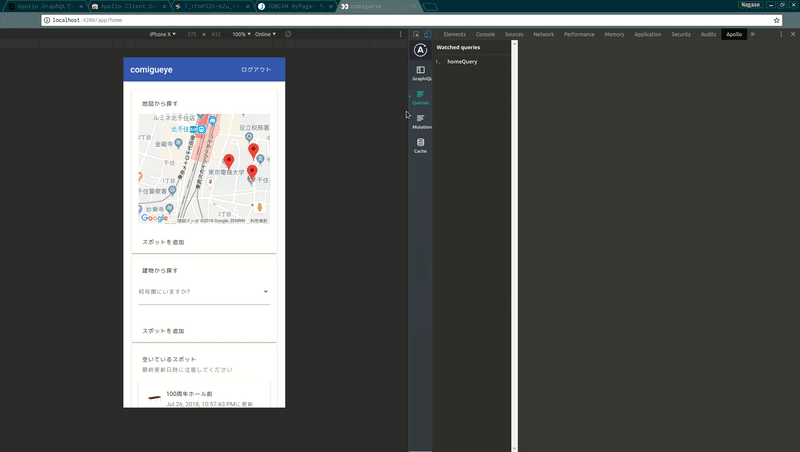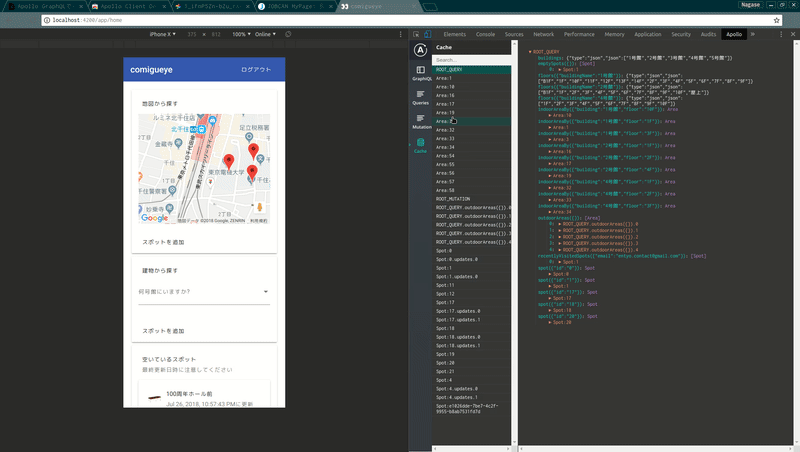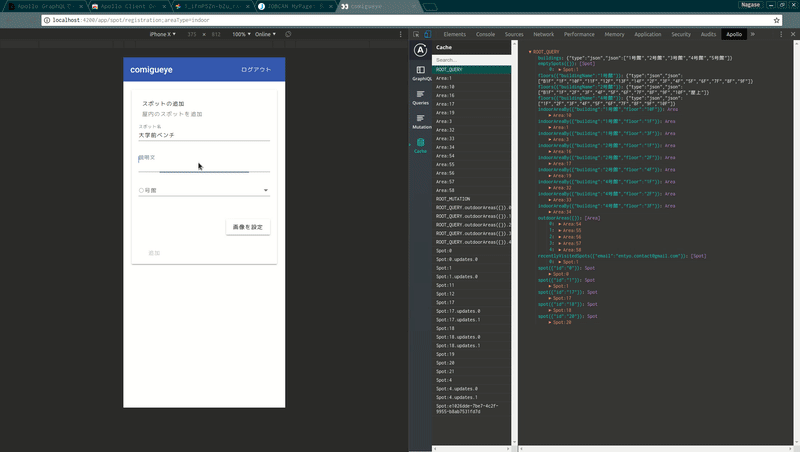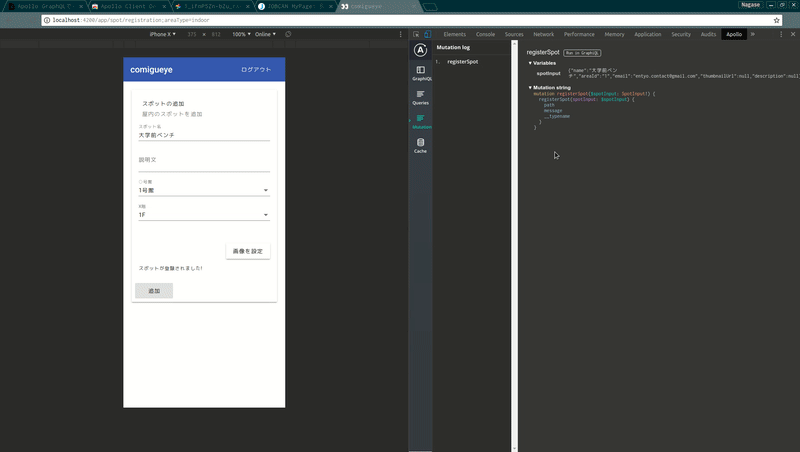
Apollo GraphQLのつらかったところ・気になったところ
特に「GraphQLのここがつらかった」というところはありませんでした…強いて言うなれば、開発の中盤で「これGraphQL APIにする意味あったんだろうか…(OpenAPIでもよかったのでは)」という気持ちに襲われたことくらいです。しかし一通り開発を終えると、エディタ・GraphiQLにおけるクエリの補完や、GraphQLが提供する型システムに魅力を見出していました。前半で解説したとおり、通信コストやパフォーマンスの点でもGraphQL APIに分があるはずです。
気になった点としては、今回はSubscriptionを使う場面がなかったため、どう実装し利用すればよいのかが気になっています。
さいごに
Apollo GraphQLを使ってゼロからWebサービスを開発し、得られた知見を共有させていただきました(どちらかというとGraphQL・Apolloの解説がメインとなってしまいましたが…)。Apolloは対応するクライアント・Webフロントエンドフレームワークが多いことから、これからより一層注目されていくと考えています。この記事を読んで「Apollo、さっそく私も試してみよう!」という方が出てきてくれたらうれしいです。
このコメントはブログの管理者によって削除されました。
返信削除