
OpenAIは7月18日、安くて軽量なマルチモーダル大規模言語モデル「GPT-4o mini」をリリースしました。テキストや画像に対応し、Gemini FlashやClaude Haiku、GPT-3.5 Turboより精度が高く高速、それでいて安価なのが特徴です。
DeepLは、言語翻訳ならびに文章校正の特化型大規模言語モデルを実装したことを発表しました。言語専門家の評価では、Google翻訳よりも1.3倍、ChatGPT-4よりも1.7倍、Microsoft翻訳よりも2.3倍、DeepLの翻訳出力が好ましいと回答したといいます。
さて、この1週間の気になる生成AI技術をピックアップして解説する「生成AIウィークリー」(第56回)では、AIとユーザーの対話内容を長期記録し、LLMの応答をそのユーザーにパーソナライズしていくメモリ機能「Mem0」や、音声の理解に優れている大規模言語モデル「Qwen2-Audio」などを取り上げます。
生成AI論文ピックアップ
音声理解を得意とする大規模言語モデル「Qwen2-Audio」をアリババグループが開発
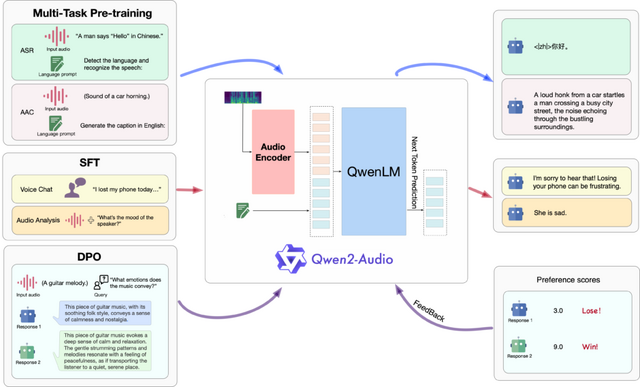
Alibaba GroupのQwenチームは、大規模音声言語モデル「Qwen2-Audio」を発表しました。このモデルは、音声処理と自然言語処理を融合させた技術で、さまざまな形式の音声入力を受け付け、高度な音声分析や音声指示に対する適切なテキスト応答を生成できます。
Qwen2-Audioの開発において、研究チームは従来の複雑な階層タグを使用する方法から脱却し、自然言語プロンプトを活用した簡素化されたプロセスを採用しました。この新しいアプローチにより、モデルの汎用性が大幅に向上し、より柔軟な指示追従能力を獲得しています。また、事前学習に使用するデータ量も大幅に増加させ、モデルの知識を拡充しています。
Qwen2-Audioは、2つの異なる音声対話モードを提供しています。音声チャットモードでは、ユーザーはテキスト入力を必要とせず、完全に音声のみでモデルと自由に対話することができます。一方、音声分析モードでは、ユーザーは音声データとテキストによる指示を組み合わせて提供し、詳細な音声分析を行うことができます。
性能評価では、Qwen2-Audioは多くの分野で優れた結果を示しました。AIR-Benchテストでは、音声、環境音、音楽、複合音声の理解と応答において、Gemini-1.5-proなどの従来モデルを上回りました。自動音声認識では、LibriSpeechデータセットで1.6%という低いWER(単語誤り率)を達成し、音声翻訳ではCoVoST2データセットで複数の言語対において従来モデルより高い性能を示しました。さらに、感情認識と音声分類のタスクでも高い精度を達成しています。

Qwen2-Audio Technical Report
Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, Chang Zhou, Jingren Zhou
Paper | GitHub
商品展示のための着せ替えバーチャルドレッシング技術「IMAGDressing-v1」
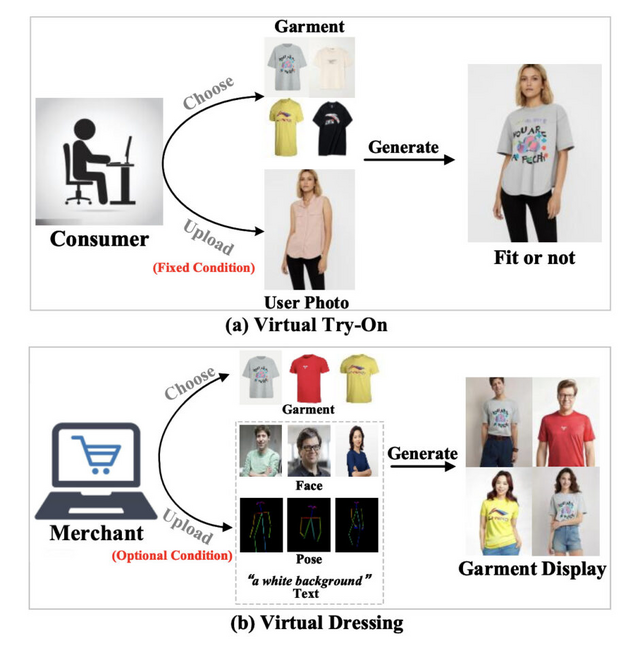
オンラインショッピングの世界で、バーチャルトライオン(VTON)技術が急速に進歩しています。しかし、これまでのVTON技術は主に消費者向けに設計されており、販売者が衣服を多角的に展示するニーズに十分に応えられていませんでした。
この課題に取り組むため、研究チームが新しい「バーチャルドレッシング」(VD)技術を開発しました。VD技術は、固定された衣服に対して、顔、ポーズ、背景などを自由に変更できる人物画像を生成することを目指しています。
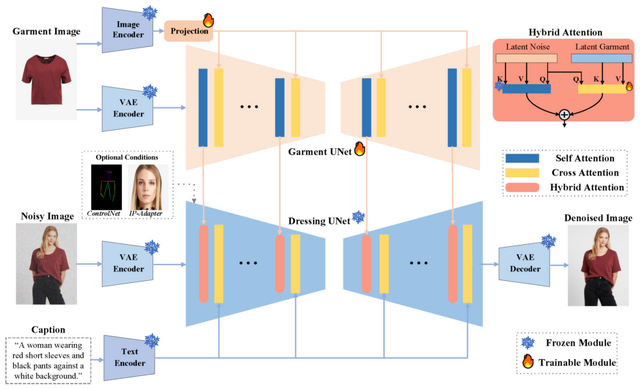
研究チームが開発した「IMAGDressing-v1」モデルは、衣服の細かな特徴を捉える能力に優れています。また、テキスト入力によって背景などのシーンを制御しつつ、衣服の特徴を適切に反映させることができます。さらにIMAGDressing-v1は、ControlNetやIP-Adapterなどの拡張プラグインと組み合わせることで、生成画像の多様性と制御性をさらに向上させることができます。
この研究の一環として、30万組以上の衣服と着用画像のペアを含む大規模なデータセット「IGPair」も公開しました。このデータセットには高解像度の画像と詳細な説明文が含まれています。
実験結果では、IMAGDressing-v1が既存の最先端技術を上回る性能を示しました。特に、衣服の細かな特徴を保持しながら、様々なシーンで自然な人物画像を生成できる点が高く評価されています。
アニメキャラクターに実際の服を着せ替えるコードも公開しています。



IMAGDressing-v1: Customizable Virtual Dressing
Fei Shen, Xin Jiang, Xin He, Hu Ye, Cong Wang, Xiaoyu Du, Zechao Li, Jinghui Tang
Project | Paper | GitHub
AIとのやり取りを記録し、ユーザーに最適化した応答内容に学習するパーソナライズAI向けメモリ機能「Mem0」
Mem0は、大規模言語モデル(LLM)向けに開発されたパーソナライズAIメモリ機能です。このシステムは、ユーザーとの対話を通じて情報を収集し、それらを基に継続的に学習することで常に進化し続けるシステムです。Mem0の中核となる機能は、AIによる自動的な記憶管理です。情報の整理や関連付けを行うだけでなく、ユーザーの使用パターンを学習して記憶の質を向上させていきます。
これにより、ユーザーごとに最適化された情報提供が可能となり、個人の興味や習慣に合わせた応答ができるようになります。使用するほどに賢くなり、より適切な情報を提供できるようになります。さらに、Mem0は異なるアプリケーション間でも一貫した記憶を維持し、シームレスな体験を提供します。
Mem0の一般的な使用事例には、個別化された学習アシスタント、カスタマーサポートAIエージェント、ヘルスケアアシスタント、バーチャルコンパニオン、ゲームAIなどがあります。これらの応用例では、長期記憶を活用して、ユーザーの好みや過去のインタラクション、進捗状況を記憶し、より個別化された効果的な体験を提供します。

Mem0: The Memory Layer for Personalized AI
GitHub
映像から動きのある3D環境に変換する技術「Shape of Motion」をGoogleなどが開発
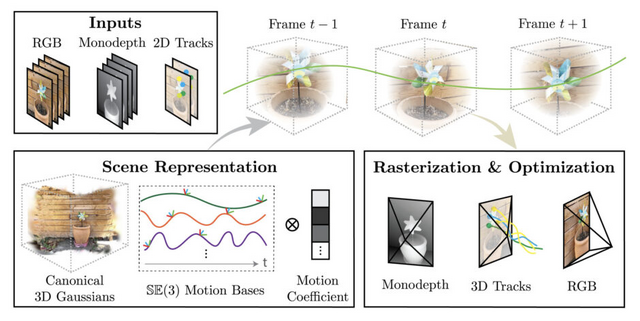
「Shape of Motion」は、単一の動画から映像が動いている3Dモデルを生成する技術です。これまで、静止した3D環境の再現は進歩してきましたが、動きのある3Dシーンを1つのビデオから再構成することは非常に難しい課題でした。
Shape of Motionの特徴は、3D空間を多数の小さな3D点(3D Gaussian Splatting)の集まりとして表現し、これらの点が時間とともに移動や回転をすることで動きを再現します。この方法により、複雑な動きのある3D環境を効率的に表現し、操作することが可能になりました。
また、単眼深度マップや長距離2Dトラッキング(ビデオ内で物体や特定の点の動きを長時間にわたって追跡すること)など、異なる情報源からの補完的な手がかりを効果的に統合し、動的シーンのグローバルに一貫した表現を実現しています。
研究チームは、合成データセットと実世界の動画データセットの両方で評価を行いました。その結果、Shape of Motionは長距離2D/3Dトラッキング精度と動的シーンの新規視点合成品質の両面で、既存の手法を大きく上回る性能を示しました。


Shape of Motion: 4D Reconstruction from a Single Video
Qianqian Wang, Vickie Ye, Hang Gao, Jake Austin, Zhengqi Li, Angjoo Kanazawa
Project | Paper | GitHub
オープンソースのLLMを商用モデルレベルの性能に向上させる方法
この研究は、オープンソースの大規模言語モデル(LLM)が商用モデルと競争できるかどうかを検証したものです。研究者たちは、BioASQチャレンジという生物医学分野の質問応答タスクを用いて、様々なモデルの性能を比較しました。
実験では、OpenAIのGPT-3.5とGPT-4、AnthropicのClaude 3 Opus、そしてオープンソースのMixtral 8x7Bモデルが使用されました。研究者たちは、これらのモデルにゼロショット学習(事前の例なしで回答を生成)、少数ショット学習(数個の例を与えて回答を生成)、そして一部のモデルには微調整(ファインチューニング)を施して性能を比較しました。
実験の結果、オープンソースのMixtral 8x7Bモデルは、10ショット学習(10個の例を与える方法)を用いることで、一部のタスクで商用モデルと同等かそれ以上の性能を示しました。これは、適切に使用すれば、オープンソースモデルが高価な商用モデルに匹敵する可能性があることを示しています。
しかし、ゼロショット学習の場合、Mixtral 8x7Bは商用モデルに及びませんでした。これは、事前の例なしで回答する能力においては、商用モデルがまだ優位性を持っていることを示唆しています。
モデルの微調整(ファインチューニング)は、必ずしも一貫した性能向上に繋がりませんでした。また、Wikipediaからの関連知識を組み込んだテストも行いましたが、パフォーマンスの向上は見られませんでした。
この研究では検索拡張生成(RAG)という技術も活用しています。RAGは、モデルが回答を生成する際に外部の知識源を参照する方法で、これにより回答の正確性が向上することが期待されます。研究者たちは、RAGと少数ショット学習を組み合わせることで、オープンソースモデルと商用モデルの性能差が縮まる可能性があると指摘しています。
実用面での重要な発見もありました。Mixtral 8x7Bを商用APIサービスを通じて利用した場合、Claude 3 Opusよりも大幅に高速で、コストも30倍以上安価でした。
Can Open-Source LLMs Compete with Commercial Models? Exploring the Few-Shot Performance of Current GPT Models in Biomedical Tasks
Samy Ateia, Udo Kruschwitz
Paper


Amazon売れ筋ランキング





















2014年から先端テクノロジーの研究を論文単位で記事にして紹介しているWebメディアのSeamless(シームレス)を運営し、執筆しています。
テクノエッジ友の会に登録しませんか?
今週の記事をまとめてチェックできるニュースレターを配信中。会員限定の独自コンテンツのほか、イベント案内なども優先的にお届けします。
0 件のコメント:
コメントを投稿