富士通研究所は、ディープラーニング(深層学習:多層ニューラルネットによる機械学習)で学習に使うメモリーの使用量を削減できる技術を開発した。メモリー使用量の40%以上を削減でき、同じメモリー量でより大規模なニューラルネットの学習ができる。既に特許を申請済みで、2016年度末までの実用化を目指す。富士通研はこの成果を、イタリアで開催された国際会議「IEEE Machine Learning for Signal Processing 2016」で2016年9月15日(現地時間)に発表した。
富士通研がこの技術を開発したのは、研究開発の対象となるニューラルネットが急速に大規模化しているためという。例えば、画像認識コンテスト「ILSVRC(ImageNet Large Scale Visual Recognition Challenge)」で2015年に優勝した米マイクロソフトのニューラルネット「ResNet」は152層構造で、学習のため最大8ギガバイトのメモリーを専有する(一度に学習させる画像が8枚の場合)。これは、2012年に優勝した「AlexNet」の13倍である。
GPU(グラフィックス・プロセッシング・ユニット)ボードが持つ専用DRAMは、2013年出荷の米エヌビディア製「Tesla K40」が12ギガバイト、2016年内出荷予定の「Tesla P100」が16ギガバイトと、大きくは伸びていない。このままニューラルネットが大規模化すれば、一つのニューラルネットをGPUボード単体で学習させることができなくなり、学習の高速化が難しくなる。
そこで富士通研究所は、演算を進める中で不要になったデータを速やかに削除することで、使用するメモリー量を削減した。以下、具体的な削減の工夫を説明する。
ニューラルネットの実体は、複数の層から成るニューロン同士の結合の強さ(重み付け)を示す「重みデータ」である。ニューラルネットを学習させることは、メモリーに記録した重みデータを修正することを意味する。

画像などの学習データをもとに重みデータを修正するには、まず学習データをニューラルネットに入力し、各層で出力される「中間データ」をメモリーに記録する。次に、ニューラルネットの出力値が、正解となる教師データに近づくよう、まず出力値と教師データの差分(誤差)を算出。この値を起点に、ネットワークを逆に辿って各層の出力値の誤差「中間誤差データ」を算出する。さらにこのデータを基に、学習後の重みデータを示す「重みデータの誤差」を得る。
「Caffe」など従来のディープラーニングフレームワークの実装では、「中間データ」「重みデータ」「中間誤差データ」「重みデータの誤差」の4つ全てを同時にメモリーに展開していた。
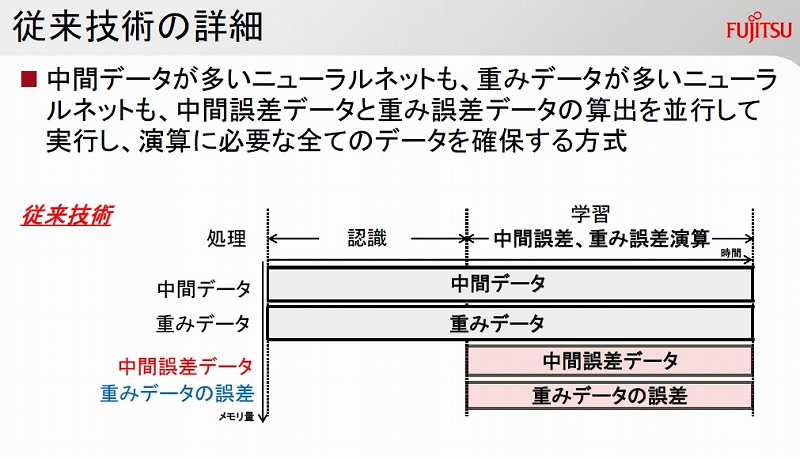
富士通研は、各ニューラルネット層で「中間誤差データ」と「重みデータの誤差」を算出する演算が、それぞれ独立していることに着目。中間データが多いニューラルネット層では、まず中間データから「重みデータの誤差」を算出し、その後に中間データを上書きする形で「中間誤差データ」を算出するようにした。重みデータが多いニューラルネット層では、まず重みデータから「中間誤差データ」を算出し、重みデータに上書きする形で「重みデータの誤差」を算出した。これにより、上書きした分のメモリー量を削減できた。
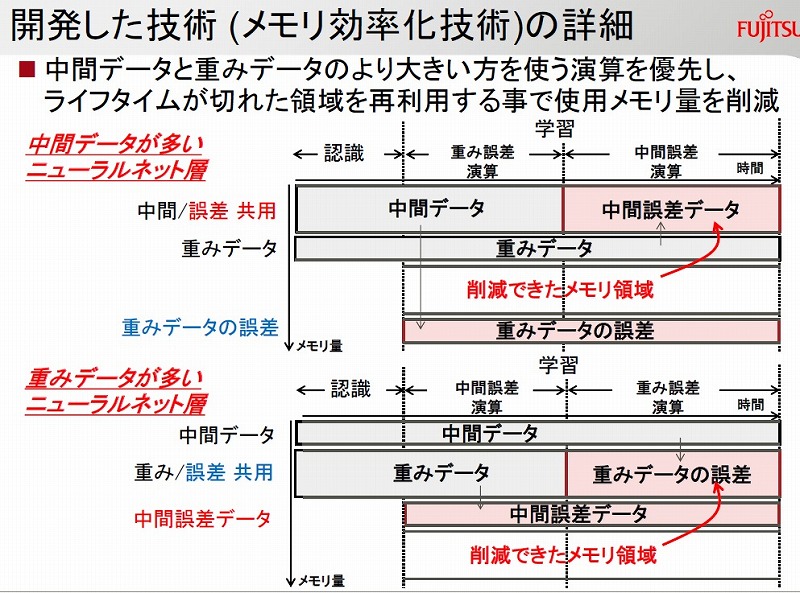
この技術をCaffeに実装し、学習認識用ニューラルネット「AlexNet」や「VGGNet」で評価したところ、メモリー使用量を40%以上削減できた。同技術は、分散処理による学習の高速化(関連記事:富士通研究所が深層学習の高速化技術を開発、GPU64台で速度27倍、「世界最高速」実現)とも併用可能という。
現在、深層学習の基礎技術をめぐる特許取得の競争は激しさを増している。例えば米国特許庁(USPTO)特許検索サイトで「Deep Learning」「Deep Neural Network」を検索すると、米グーグルや米マイクロソフトが少なくとも深層学習関連で数十の特許を成立させていることが分かる。リレーショナルデータベースなどかつての研究分野と同様、人工知能(AI)の商用化でも特許戦略がその成否を分ける可能性がある。
0 件のコメント:
コメントを投稿