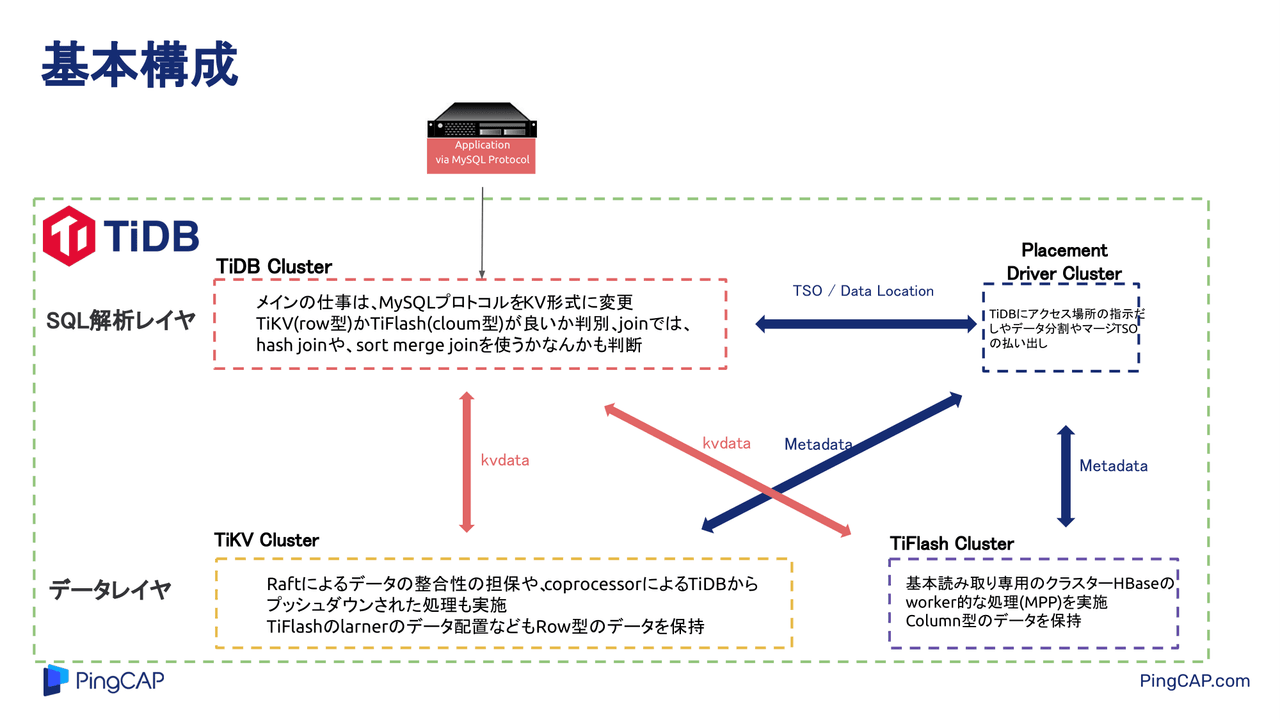
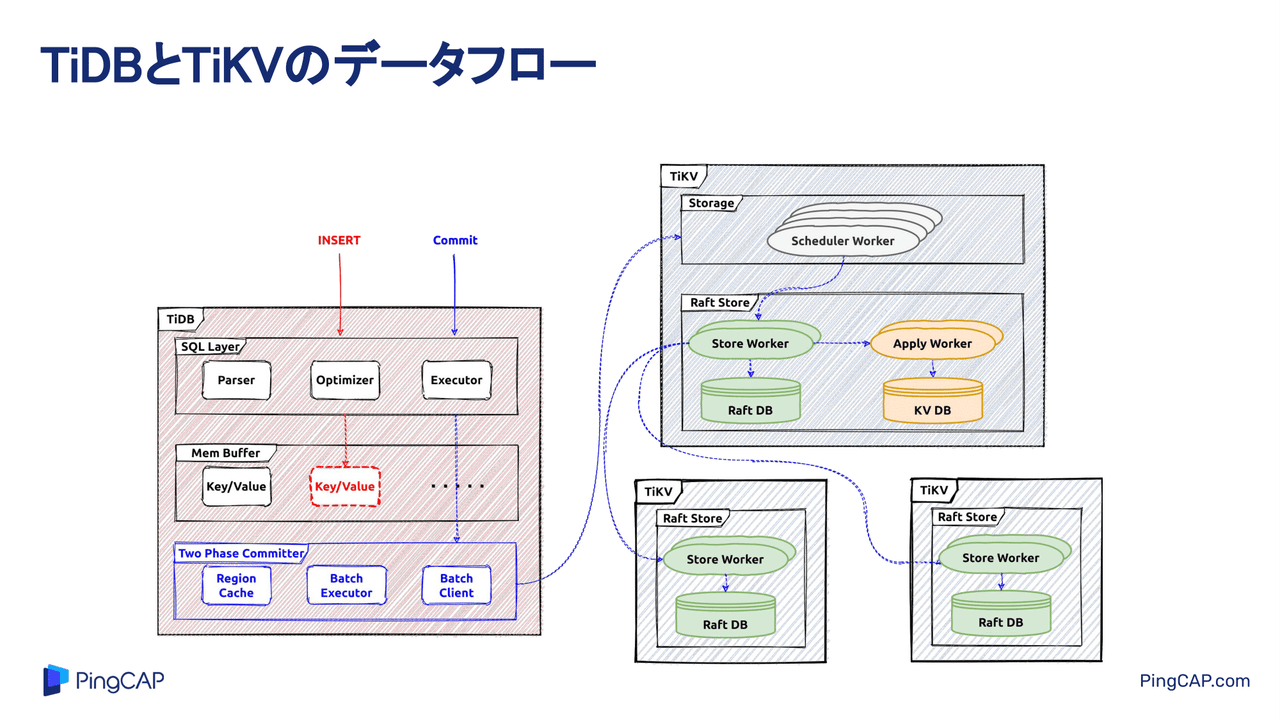
Cloud Nativeなシステムを構築するにあたって手助けとなる、アプリケーション開発と運用のアジリティ、可用性、拡張性を支えるさまざまなデータベースを学ぶ「Cloud Native Database Meetup #1」。ここで「TiDBのトランザクション」をテーマに水戸部氏が登壇。まずはTiDBの特徴と基本構成について紹介します。 水戸部章生氏:ここからは、PingCAPでプリセールスを担当している水戸部が、TiDBの紹介をします。本日は、Cloud Native Database Meetupの1回目です。PingCAPジャパンは4月に法人を設立し、日々TiDBの布教活動を行っています。その中で、少しでも私たちの製品を知ってもらえればと思っています。 (スライドを指して)このページにキャラクターが映っていますが、みなさんが見ている画面の右側にキャラクターの投票QRがあるので、選んでもらえると非常にうれしいです。ちなみに、私が推してるキャラクターは真ん中の鯛です。資料の中で何回か出てくるので、ぜひと思っています(笑)。 自己紹介をします。先ほど話したとおり、私はPingCAPでプリセールスを担当している水戸部です。前職では、ハードウェアやゲームの会社でデータベースやハードウェアを触っていたので、そのような部分も含めて紹介できればと思っています。 本日のアジェンダです。まず、TiDBとはどのようなものか。次にTiDBの基本構成。さらに、本日の主題となるTiDBのトランザクションについてです。東京、大阪、ソウルのリージョンで分散配置して、1つのリージョンを落としてみた時、どんな挙動になるのか。簡単ですが実施した結果があるので、そちらを見てもらえればと思います。 みなさんはあまり知らないと思いますが、TiDBと呼ばれるクラウドネイティブなSQLデータベースの4つの特徴を挙げます。 1つ目は、クラウドの利点を徹底的に活用するアーキテクチャーです。水平分割や垂直分割などをサポートできます。2つ目は、マイクロサービス向けのKubernetes環境のほか、TiDB Operatorと呼ばれるアドミンに入れて、DaaS(Desktop as a Service)のようなことができるPodも用意しています。 3つ目は、2016年に作ったデータベースなので、非常にモダンな技術を採用しています。RustやGoのほか、gRPC、Raftのような新しいアーキテクチャーです。Rustに関しては、弊社にはコアのエンジニアが2人ほど所属しています。もしデータベースではなくRustの言語について知りたい方がいれば、声をかけてもらえたらうれしいです。 4つ目は、マルチプラットフォームで実装可能なことです。さらに、フルマネージドのサービスも持っているのがTiDBの特徴です。 データベースについてもう少し話すと、こちらはHTAP(Hybrid Transaction Analytical Processing)が可能な分散型SQLデータベースです。(スライドを指して)オンライン拡張とリアルタイム分析ができるのが特徴で、左側のOLTP(Online Transaction Processing)に関しては、シングルのデータベースで400TB以上拡張が可能です。また、シングルのテーブルで数兆レコードまで対応できるのが特徴です。 右側のOLAPは、左側にあるOLTPのデータをリアルタイムに分析できるHTAPの製品であることも、TiDBのデータベースの特徴の1つです。 TiDBには技術的に、また運用面でどのようなメリットがあるかを少し紹介します。1つ目は、MySQL互換のデータベースです。特にプロトコル互換をしているので、今までMySQLを使っていたお客さんなら、新しくクエリを勉強することなく使えるのが大きなポイントの1つだと思っています。 2つ目の特徴として、オンラインでDDL変更ができます。3つ目から6つ目は、Raftのアルゴリズムを使っています。Raftのアーキテクチャーを使うことによって、オンラインのスケールアウト、書き込みスケール、読み込みスケール。また、逆にオンラインスケールインもできます。 そのほか、データの自動化分散やシングルのデータベースで、データのDR(Disaster Recovery)配置も可能です。最後のおまけで、どのような動きになるかを見てもらえればと思っています。 7つ目は、Raft上で、デフォルトでリーダーのみ読み込み書き込みにするのがTiDBの特徴なので、リード読み込みのレプリ遅延がないのは、運用上、非常にポイントが高いと思っています。私も昔はゲームでMySQLデータベースを使っていましたが、リードレプリカの遅延を考慮しなかった結果、箱庭系のゲームで庭にたくさんの木が生えた事件も起こったので(笑)。リード読み込みのレプリ遅延がないのは、運用の中ではいいと思っています。 続いて、TiDBの基本構成です。(スライドを指して)この緑色で囲まれた部分が、TiDBのコンポーネントです。この中にそれぞれ必要なClusterを記載していますが、一番上はSQL解析レイヤーです。 TiDBの場合は、SQLを解析するClusterとデータ、KV(Key-Value)を扱うClusterが分かれた設計になっています。上部のSQL解析レイヤーは、クエリの増加によってノードを追加して対応するClusterです。 その下がTiKV Clusterです。こちらは容量拡張やI/Oの拡張で、ノードを追加して対応していきます。ほかに、横にあるデータレイヤーのClusterは、OLAP用カラムデータの読み取り専用として配置するものです。 右上は、私たちのTiDBの中ではキーとなる、Placement Driver Clusterコンポーネントです。このPlacement Driverが、それぞれのRaftの負荷分散やラインナズブルをするためのタイムスタンプを発行します。Placement Driverが各Clusterと連携する設計になっています。 また上に矢印を書いていますが、それぞれのノードはアプリケーション、MySQLプロトコルを使って、書き込みや読み込みができます。デュアルマスターのような動き方をする基本構成です。 では、それぞれのClusterで、どのような仕事をしているのか紹介しようと思います。1つはTiDB Clusterで、メインの仕事はMySQLプロトコルをKV形式に変更することです。 ただ、中にはオプティマイザーの役割を持っているものもあるので、TiKV、Row型を使ったほうがいいのか、それともカラムを使ったほうがいいのかの判別も行っています。例えば、テーブルフルスキャンが必要な時は、TiFlashからデータを持ってきます。 そのほかに、joinなどではhash joinやsort merge joinを使う必要があるかも、TiDB Cluster、SQL解析レイヤーで判別しています。 (スライドを指して)その下はKVS(Key-Value Store)、NewSQLの分野なのでKVになりますが、TiKVのClusterでは、Raftによるデータの整合性の担保を行っています。本日は、トランザクションメインで紹介するのでRaftのアルゴリズムは割愛しますが、このアルゴリズムによって整合性を保っています。 そのほかの役割として、CoprocessorもTiKVに入っていて、TiDBでプッシュダウンされた処理もTiKVで行うようになっています。また、RaftのlarnerをTiFlashに書き込む作業も行う、Row型のデータを保持しているClusterです。 (スライドを指して)横にあるTiFlash Clusterは、基本的に読み取り専用のClusterです。こちらにもCoprocessorが入っていて、HBaseのworker的な処理、MPP(Massively Parallel Processing)を実装しています。Column型のデータを保持しているので、今までHBase的な動きでプログラムを組んでいた部分もTiFlash側でサポートできます。 Clusterがすべて連携してPlacement Driver Clusterになりますが、TiDBに対し、それぞれのRaftのリーダーへアクセス場所の指示出しや、データ分割やマージなども行います。 TiDBのRaftのデフォルトのサイズは32MBです。96MBまでリージョンのサイズが大きくなると、Placement Driverが指示を出して分割し、逆に20MB以下になると、マージをして一定の負荷があたるサイズで運用する仕組みになっています。 後ほど紹介しますが、Placement Driver Clusterでは、TSO(TCP Segmentation Offload)と呼ばれるタイムスタンプを発行し、トランザクションの制御も行います。これらが基本構成です。 (スライドを指して)下にあるTiFlash はAP処理用に追加するClusterです。通常のOLTPのみ利用しているお客さんは、TiDB ClusterやPlacement Driver、TiKV Clusterを使ってもらうことになります。 本日はトランザクションの話なので、このTiDBとTiKVの青い部分の紹介をしようと思っています。TiDBはSQLレイヤー、Mem Bufferレイヤー、Two Phase Committerの3つのレイヤーを備えています。 基本的には、データをINSERT、updateなどするとMem Bufferに登録されます。Mem Bufferに登録されたデータをcommitする時に、それぞれのデータをバッチ処理としてまとめ、無駄のないように送り出すような仕組みです。
クラウドネイティブなSQLデータベース「TiDB」 リード読み込みのレプリ遅延がないDBの特徴4つと基本構成
自己紹介とアジェンダ


TiDBの4つの特徴

TiDBのメリット
 TiDBの基本構成
TiDBの基本構成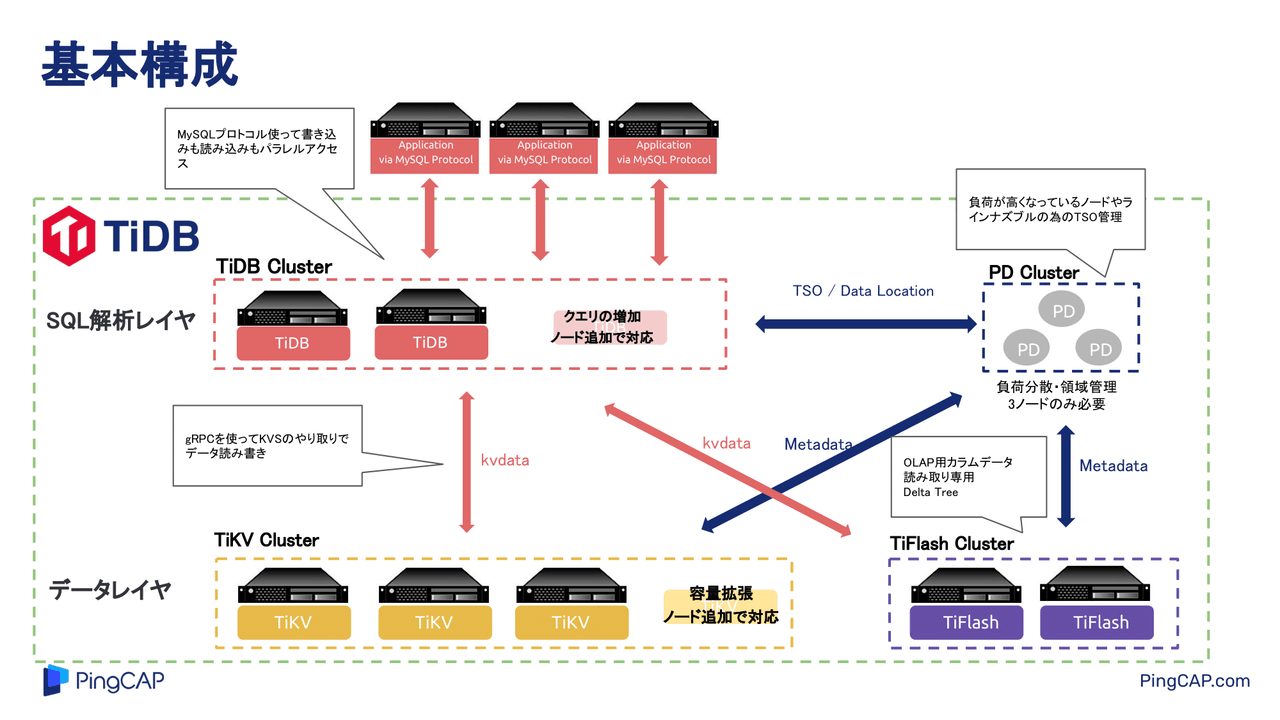
それぞれのClusterでどのような仕事をしているか





(次回につづく)









0 コメント:
コメントを投稿