シェアしました。
はじめに
データサイエンティストでなかったとしても、数値データを使って様々な解析をする際には CSV ファイル等ファイルを読み込み、数値の配列としてメモリに保持して、それらをループ等で利用して解析を行っておられると思います。
その際、配列は1次元目に行、2次元目に列、を格納するのが一般的です。多くのケースではこの方法で事足りるのですが、解析を行ううちに「列としてデータの固まりを扱いたい」「ラベル付けされた列を扱いたい」と感じる事が出てくると思います。
これを簡単にしてくれるのが「データフレーム」です。
データフレーム4種
本記事では Go 言語から扱えるデータフレームを4つご紹介します。
QFrame
QFrame は、フィルタリング、集計、およびデータ操作をサポートするイミュータブルなデータフレームです。 QFrame での操作は、それ自身が新しい QFrame となり元の QFrame は変更されません。データの多くがこの2つのフレーム間で共有されるためかなり効率的に実行できます。
QFrame は色々なケースで扱えるとても便利なライブラリです。CSV、SQL、JSON が扱え、しかも透過的に処理する事ができます。
例えばこんな JSON を扱う事も多いと思います。
この JSON を読み込み、不必要な
comment と id のカラムを消し、age と name のカラムだけを残して age でソートされた CSV を出力する場合、皆さんだとどの様に処理するでしょうか。QFrame であればとても簡単です。
とても直感的ですね。例えば
ToCSV を ToJSON に変更すると以下の様に出力されます。
※整形しています
この様に、与えられた入力に対してとても直感的な操作が QFrame のウリです。
Apache Arrow & bullseye
Apache Arrow はマルチプラットフォームで動作するメモリ内データ向けのライブラリです。ハードウェア上で効率的な分析操作を行える様に設計されており、メモリが断片化しないよう工夫されています。現在サポートされている言語には、C、C ++、C#、Go、Java、JavaScript、MATLAB、Python、R、Ruby、および Rust が含まれています。

要はデータをカラムで持ち(カラム指向またはカラムナーと言います。えっ言わない?ちょっとした事で絡むな~)、データを扱いやすくしている訳です。さらにサイズを固定化してフラットにする事で、オフセットによる瞬時なアクセスを可能にしています。
bullseye は Apache Arrow で構築されたメモリを扱う為のデータフレームです。
Apache Arrow はデータの型をとても意識したライブラリです。データを投入するにはまずスキーマを定義する必要があります。例えば iris のデータセットであれば以下の定義になります。
データを投入する際はメモリプールを生成して読み込みます。iris のデータを読み込み、種別を一覧するコードは以下の様になります。
ちょっと冗長な感じがしますが、例えば不正なデータが投入されるかもしれない入力データを扱うには便利です。また Apache Arrow はメモリブロックを必要な単位で切り出してフレームを構成しているので、断片化が起きにくく処理速度も高速です。大量のデータを扱うのであれば Apache Arrow と bullseye を使うのが良いと思います。ただし癖が強いので慣れるまでが大変です。
dataframe-go
dataframe-go も直感的な操作を売りにしています。まだ安定版ではないとの事ですが、以下の特徴があります。
- CSV, JSONL, MySQL, PostgreSQL からのインポート
- CSV, JSONL, MySQL, PostgreSQL へのエクスポート
- 開発しやすさ
- カスタムシリーズを作れるなどのフレキシブルさ
- パフォーマンス優先
- gonum との相互運用性
API は Select が無いなど、幾分物足りない感がありますが、RDBMS や gonum との連携がウリの様なので今後に期待したい所です。
dataframe はそのまま
fmt.Println すると綺麗な表になってくれます。
※ Gota や qframe も同様です
Gota
Gota は DataFrames、Series および data wrangling (マッピング等の加工)メソッド群の実装です。とても分かりやすく直感的で、これら4つの中では一番 Go らしいライブラリだと思います。Gota の操作については、@thimi0412 さんが分かりやすく解説してくれた記事があります。
ただし記事の中で登場する Gota のリポジトリは現在
github.com/kniren/gota から github.com/go-gota/gota に変更になっているのでご注意下さい。
僕はこれまで Gota をよく使ってきました。JSON や CSV を読み込む機能は他のデータフレームにもありますが、特に struct binding が便利なので、既存のコードにデータフレームを使った処理を追加する際に Gota は威力を発揮します。例えば User struct の配列から欲しいフィールドだけを集めて JSON にするのであれば以下の様になります。
また iris の CSV を読み込んで種別を数値化(Bug of words)するのであれば以下の様になります。
ベンチマーク
上記のデータフレームライブラリの内、QFrame と Gota でベンチマークを取ってみました。Apache Arrow および bullseye は CSV を読み込む機能こそ用意されていますが、作ったレコードを再度 CSV に出力する為の機能が備わっておらず、自らレコードを作り直さないといけなかった為、このベンチマークからは除外しました。
結果は Gota や dataframe-go よりも QFrame が2~3倍ほど速い結果になりました。この要因として、QFrame が出力する CSV の形式が
の様な数値の形式であるのに比べ Gota は
の様な若干冗長な形式になっているのも起因してる様です。dataframe-go が遅いのはソースを見たところ RemoveSeries でのコピー量が多い様です。
pairplot
これはデータフレームではありませんが、Python の seaboan.pairplot をGo言語に移植した go-pairplot というライブラリがあり、先日これを Gota を使う様に変更しました。以前までは扱える型を float64 に限定していた為、精度の必要ないデータや文字列を扱うデータでは使いどころが難しかったのですが、データフレームを使う様に変更した事でとても便利になりました。

もちろん Jupyter Notebook からGo言語を扱える gophernotes からでもこの go-pairplot は扱える様にしてあります。
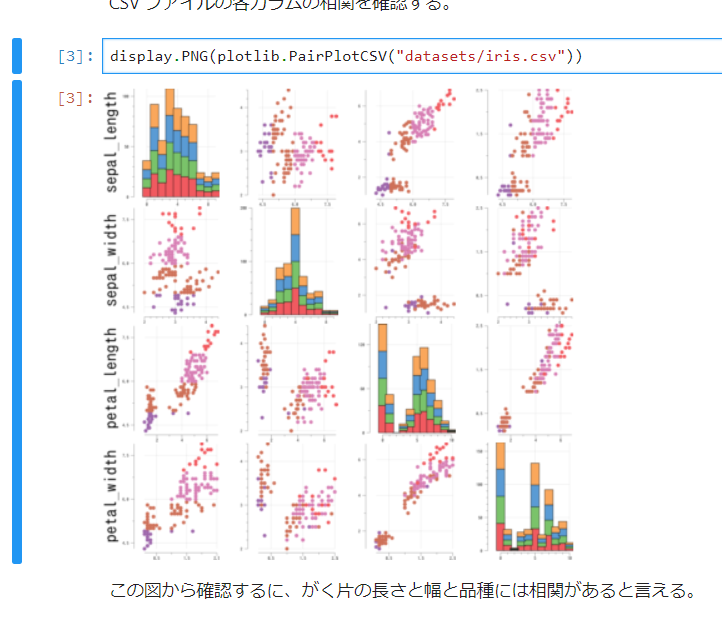
また go-plotlib を使うと Jupyter Notebook 上で CSV を簡単に表示できます。
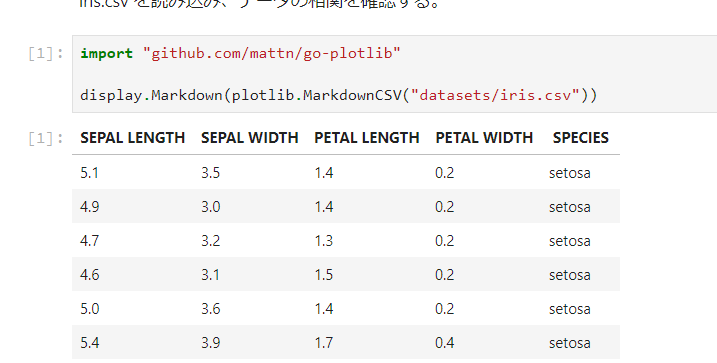
Go言語でデータサイエンスをする際はお役立て下さい。
まとめ
Go言語で扱えるデータフレームライブラリを4つご紹介しました。それぞれに特色があり、やりたい処理によって選ぶ必要があります。小規模から中規模のデータで、カラムを自在に操りたい場合は QFrame または Gota、巨大なデータを高速に扱いたいのであれば Apache Arrow と bullseye の組み合わせという選択になると思います。
中規模までのデータに関しては、パフォーマンスを求めるのであれば QFrame が良いです。Gota は Go の struct binding もサポートしていますし、おそらく皆さんがやりたいと思うであろう機能が一通りそろっているので、データフレームがどんな物か触ってみたいという方はまず Gota を触ってみるのをオススメします。










0 コメント:
コメントを投稿