勉強の為に引用しました。
(I quoted it for studying.)
http://postd.cc/the-way-of-the-gopher/
Node.jsからGo言語への移行
私は大学時代に、興味本位でJavaScriptを始めて、それ以来ウェブページを幾つか作成してきました。JavaScriptは常にC言語やJavaの合間の楽しい息抜きでしたが、アニメーションや、ユーザをあっと言わせるようなちょっとしたことを提供するといった、特殊な目的にかなり限られた言語だと考えていました。JavaScriptは覚えやすく、開発者に具体的な結果をすぐにもたらしてくれるので、コーディングする方法を学びたいと思っている人に私が教えた最初の言語でした。JavaScriptにHTMLとCSSを少し組み合わせれば、ウェブページが出来上がります。プログラミング初心者には喜ばれます。
その後、あることが2年前に起こりました。当時、私は、主にサーバーサイドのコードとAndroid用のアプリのプロトタイプに取り組む研究職に近い立場にいました。すぐにNode.jsの存在が目に留まりました。バックエンドJavaScriptですって? 誰が真剣に受け止めるでしょう? それは、せいぜい、パフォーマンス、スケーラビリティ、その他を犠牲にしてサーバーサイドの開発をより簡単にするための新たな試みのように思えました。開発者に染みついた単なる疑り深さなのかもしれませんが、速くて、簡単で、本番で十分運用できるレベルにあるものと聞くと、いつも頭の中で警報が鳴ります。

注釈:「ヘタな通販みたいだ」

注釈:「あの最悪な×××みたいだな」
そういうわけで、研究、テスティモニアル、チュートリアル、サイドプロジェクトに取り組んで6カ月後、気が付いてみると初めてNode.jsを知ってから、それしかやっていなかったのです。特に2、3カ月ごとに新しいアイデアのプロトタイプを作ることに従事していた時からずっと、Node.jsはあまりにも簡単でした。しかし、Node.jsはプロトタイプや入れ込んでいるプロジェクトだけに向いているわけではありません。Netflixのような大手企業でさえ、Node.jsを実行している自前のスタックを持っていました。突然、世界は釘でいっぱいになり、私はハンマーを見つけました。
さらに数ヶ月を早送りすると、私は現在Diggのバックエンド開発者として働いています。私が加わった2015年4月当時、Diggのスタックは、2つのサービスを除いて主にPythonでした。その2つのサービスは、なんと、Node.jsで書かれていたのです。私はパイプラインで問題を引き起こしていたサービスの1つを調整する仕事を割り当てられ、さらにもっと感激しました。
私たちの厄介なNodeサービスは、非常に簡単な目的を持っていました。DiggはAmazon S3を使用しています。S3は、バッチのGET操作をサポートしていない以外は、すばらしいストレージです。S3から一度に100件以上までのキーをリクエストするために、自分たちのPythonのウェブサーバー上に全ての負荷を負わせるより、Node.jsの簡単な非同期コードパターンと優れた並行処理を利用することに決まりました。そしてOcto、S3コンテンツ取得サービスは誕生しました。
Node版Octoは正常な時はよく動きました。1日1回、1分当たりのリクエストが50件から200件以上にまで跳ね上がるトラフィックのスパイク(急激な増加)を処理する必要がありました。さらに、リクエストごとに、Octoは、大抵、10~100件までのキーをS3から取得していたのです。すなわち、それは1分間に2万回のS3のGET操作を処理する可能性があるということです。このトラフィックのスパイクが発生している間、当社のサービスが大幅に低下することを、ログは示していました。しかし、問題はそれが必ずしも回復しないということでした。このように、Octoが止まって完全に機能しなくなると数週間ごとにEC2インスタンスを回復させなければならない状況に陥っていました。
サービスに対するリクエストには、厳しいタイムアウト値も設定されています。リクエストを受信してからクロックがXミリ秒経過すると、Octoは、S3から正常に取得したものをクライアントに返して次に進むことになっています。しかし、最大タイムアウトを1200msに設定しても、Octoのリクエスト処理時間が最悪10秒まで上昇しました。
コードは非同期の処理が多く、さらに、S3のキーの値を積極的にキャッシュしていました。Octoはまた、2つのメディアを使い、4つまで増やしたEC2インスタンス間で走っていました。
私は最後の1滴まで性能を絞り出すために、Node.jsの最適化、落とし穴、トリックをこれまで以上に深掘りし、3回コードを書き直しました。ExpressやHapiなど人気のあるNodeウェブサーバフレームワーク対Nodeの組み込みHTTPモジュールのベンチマークを見直しました。あると便利でありながらコードの実行を遅くするサードパーティのモジュールを削除しました。結果は、3回とも全て同じ問題に苦しむという繰り返しでした。どんなに一生懸命試しても、Octoを正しくタイムアウトさせることはできませんでした。リクエストのスパイクが発生している間、性能の低下を抑えることもできませんでした。
ようやく、理屈が分かりました。それはNode.jsのイベントループの動き方に関係していました。イベントループをご存知ない場合は、Node Sourceで情報を得ることができます。
Node.jsの”イベントループ”は高スループットのシナリオを処理する中枢であり、ユニコーンや虹で満ちあふれた魔法の国です。このイベントループによって、任意の数の操作をバックグラウンドで処理できるにもかかわらず、Node.jsは基本的に”シングルスレッド”なのです。

魔法の国とは言えないイベントループのブロッキング(x軸:ミリ秒時間)
ユニコーンと虹が全て消えてしまい、サービスを回復させると再び戻ってくるのが、このグラフから分かるでしょう。
数ある原因の中で最大のものがイベントループのブロッキングだと分かったので、あとは、そもそもなぜ渋滞になったのかを突き止めるだけでした。
大抵の開発者は、NodeのノンブロッキングI/Oモデルについて、実行をブロックせず、また(スレッドやプロセスのように)オーバーヘッドを発生させることもなく、すべてのリクエストを非同期に処理する素晴らしいものだという話を耳にしたことがあり、開発者としては、バックエンドで何が起こっているかは知らなくても気楽にしていられます。でも、Nodeがシングルスレッドだということを常に念頭に置いておくことが重要です。つまり、コードは並列には実行しないのです。I/Oはサーバをブロックしないかも知れませんが、コードは確実にサーバをブロックします。5秒間のスリープを呼び出せば、その間、サーバは応答しなくなります。
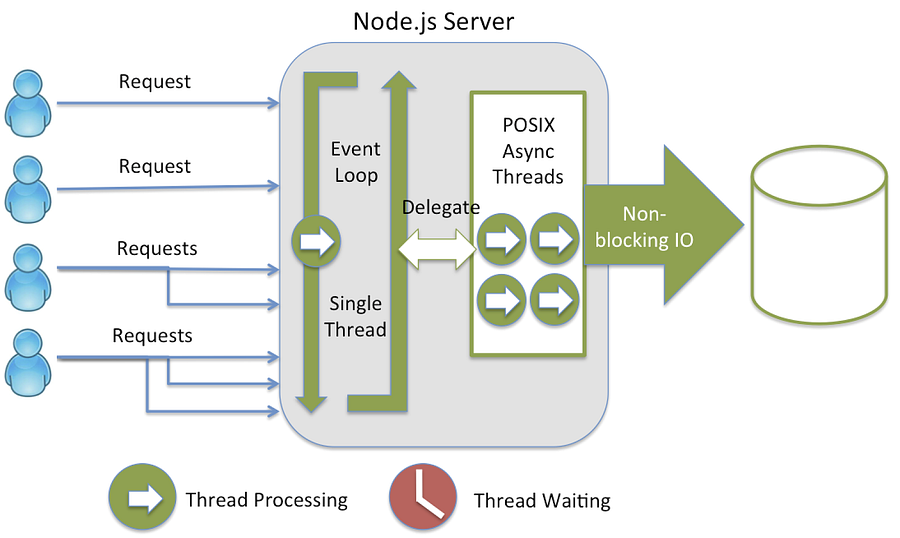
イベントループの図解―StrongLoop
ノンブロッキングコードはどうなっているのでしょうか? リクエストが処理され、イベントがトリガされると、それぞれのコールバック関数と共にメッセージがキューイングされます。詳しい説明が、鋭い洞察に満ちたブログ記事Carbon Fiveのブログ記事からの抜粋にあります。
ループ内で、次のメッセージを求めてキューがポーリングされ(各回のポーリングは「tick」と呼ばれます)、メッセージが見つかると、そのメッセージについてコールバックが実行されます。このコールバック関数の呼び出しは、コールスタック内の初期フレームの役割をし、JavaScriptはシングルスレッドなので、次のメッセージのポーリングと処理は、スタック上の全ての呼び出しの戻りを待ちつつ休止します。後続の(同期)関数呼び出しは、新しいフレームをスタックに追加します…
利用可能なデータを即座に返すことだけが必要だったのなら、私たちのNodeサービスは受け取ったリクエストを手際よく処理できたかもしれません。でも、実際には、サービスはネスティングされた山ほどのコールバックを待ち続けていて、そのコールバックは皆、S3からの応答(恐ろしいほど遅いことが時々ある)に依存していました。その結果、リクエストのタイムアウトが発生した場合、そのイベントとそれに関連するコールバックが、既にオーバーロードになっているメッセージキューに加えられます。タイムアウトイベントは1秒で発生するかもしれないのに、コールバックの処理は、現在キューにある他の全てのメッセージとそれらに関連するコールバックコードの実行が完了するまで(おそらく数秒後)始まりません。リクエストスパイクの期間中のスタックの状態は想像するしかありませんでした。でも実は、想像する必要もなかったのです。CPUプロファイルのほんの一部を見れば、かなり鮮明な像が見られます。お手数ですが、スクロールしてご覧ください。
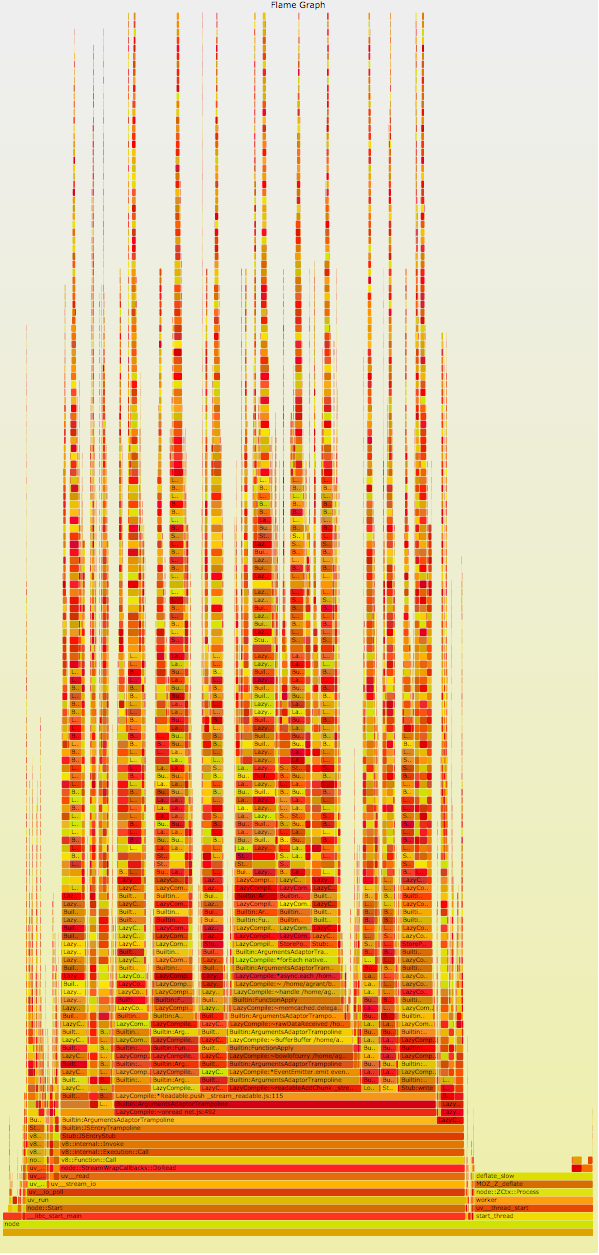
燃え上がる障害
この火炎のようなグラフを簡単に説明すると、y軸はスタック上のフレームの数を表し、各関数はその関数の上にある関数の親です。x軸は、時間の経過よりもサンプル母集団に関係します。CPU上の合計時間を示すのはボックスの幅で、幅が広いほど遅い関数を示すか、単にその関数が頻繁に呼び出されていることを示します。Octoの火炎グラフを見れば、スタックの深いところに巨大なスパイクがあることが分かります。プロファイリングと火炎グラフの詳細については、こちらを参照してください。
こうした実感に照らして、Node.jsがこの仕事のための完璧な候補ではないかも知れないとの考えを抱くようになりました。CTO(最高技術責任者)と私は、選択肢について話し合いました。一週間おきにOctoを立ち直らせることを続けたくはありませんでした。そして、インターネットで見つけた有望な事例に、2人とも大いに関心を持ちました。
Handling 1 Million Requests per Minute with Go
Here at Malwarebytes we are experiencing phenomenal growth, and since I have joined the company over 1 year ago in the…marcio.io
Goで毎分100万リクエストを処理する
Here at Malwarebytes we are experiencing phenomenal growth, and since I have joined the company over 1 year ago in the…marcio.io
Goで毎分100万リクエストを処理する
このタイトルが人をからかっているのではないのなら、S3へのPUTリクエストを行うためのサービスを作成することに関する話題でしょう(他の人も同じ問題を抱えているんですね?)。スタックのどこかにGo言語を使うことについて話し合ったのはこれが最初ではなく、この時点で、完璧なテスト対象ができました。
私にとって最初の2週間はGo言語入門の短期集中コースのようなものでした。その後、生まれ変わった新しいOctoサービスが始動し、動作していました。私はMalwarebyteのGo言語に関する概説記事のソリューションに触発され、それに忠実にサービスをモデリングしました。サービスにはワーカのプールと、受け取ったジョブをアイドリング状態のワーカに渡すデリゲータがあります。各ワーカはそれぞれのgoroutine上で実行し、ジョブが終了するとプールに戻ります。簡潔かつ効率的です。結果は即効的で、目を見張るほどのものでした。
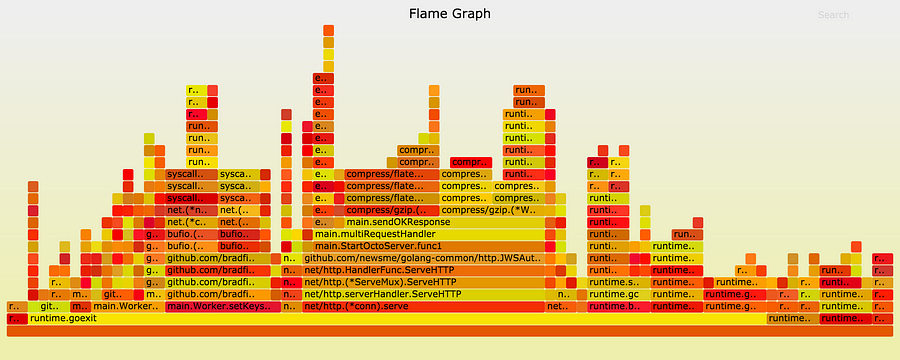
ほどよく沈静
サービスからの平均応答時間はほぼ半分になり、タイムアウト(S3の応答が遅い場合)は時間どおりに発生し、サービスへのトラフィックスパイクの影響は最小化されました。

青=Node.js版Octo|緑=Go言語版Octo
Go言語によるアップグレードのおかげで、毎分200個のリクエストを処理し、1日150万のS3アイテムをフェッチすることが簡単にできるようになりました。では、ロードバランスしながらOctoを実行させていた最初の4つのインスタンスはどうなったでしょうか? 同じことを2つのインスタンスでできるようになりました。
Go言語に移行してからは、後ろを振り返ることはありませんでした。私たちのスタックの大部分はPythonで書かれているので(また、おそらく、これからもずっとそうなので)、コードベースのモジュール化と、システム内で特定の役割を処理するためのマイクロサービスの高速化の工程を開始しました。Octoの他に、現在、リアルタイムメッセージシステムを強化し、コンテンツのための重要なメタデータを提供する3つのGo言語サービスを作成中です。Go言語コードベースに加えた自慢の最新サービスはDiggBotです。
Go言語は、あらゆる問題の特効薬というわけではありません。私たちは、個々のサービスが必要とするものを注意深く考慮しています。会社として、新しく生まれる技術の頂点に立ち続けるために、また、よりよい方法はないのか常に自問するために努力を怠りません。この努力は絶えず進化し、注意深い研究と計画を要するプロセスです。
Octoサービスが始動して数ヶ月間動作し、優れた結果が得られています(多少のバグ修正はありましたが)。このストーリーはハッピーエンドを誇ることができました。そして今、DiggはGopherの道を歩んでいます。










0 コメント:
コメントを投稿