https://eetimes.itmedia.co.jp/ee/articles/2403/08/news162.html
https://eetimes.itmedia.co.jp/ee/articles/2403/08/news162.html
(1/3 ページ)
ルネサス エレクトロニクスは、AI(人工知能)アクセラレーター技術「DRP-AI」の最新世代などを開発。同技術を搭載したビジョンAI用プロセッサ「RZ/V2H」を発表した。高い電力効率を高速な推論処理を両立できることが特徴だという。
ルネサス エレクトロニクス(以下、ルネサス)は2024年2月22日、独自のAI(人工知能)アクセラレーター技術「DRP-AI」の最新世代と、DRP-AIやCPUなどを協調動作させるヘテロジニアスアーキテクチャを発表した。いずれも、ルネサスが同年2月21日(米国時間)に半導体の国際学会「ISSCC 2024」で発表したものになる。
枝刈り処理に最適化した「DRP-AI」
DRP(動的再構成プロセッサ)は、ルネサス独自の技術で、チップ内の演算器の回路情報を処理内容に応じて動的に切り替えるもの。必要な回路だけを動作させるので、高速かつ低消費電力の演算が可能になるという。DRPと積和演算ユニットを統合し、AI処理性能に特化したアクセラレーター(AIアクセラレーター)が、DRP-AIだ。
今回ルネサスが発表したDRP-AIは、ディープラーニングモデルを軽量化する手法の一つである枝刈り(プルーニング)処理に最適化したもので、第3世代となる(以下、DRP-AI3)。2022年12月に発表した第3世代のDRP-AIをさらに改善した。
 「DRP-AI」のアーキテクチャ。右側の積和演算ユニット(MAC unit)に、枝刈り処理を効率よく行うための仕組みが搭載されている。左側のDRPと連携することで、設計時に想定していなかった新しいAIモデルやAI処理に柔軟に対応できるようになる[クリックで拡大] 出所:ルネサス エレクトロニクス
「DRP-AI」のアーキテクチャ。右側の積和演算ユニット(MAC unit)に、枝刈り処理を効率よく行うための仕組みが搭載されている。左側のDRPと連携することで、設計時に想定していなかった新しいAIモデルやAI処理に柔軟に対応できるようになる[クリックで拡大] 出所:ルネサス エレクトロニクス枝刈りは、推論精度に影響が少ない演算不要のノード(枝)をスキップし、演算回数を減らす技術だ。ただ、この演算不要のノードはAIモデル内にランダムに存在する。そのため、並列処理によって演算を高効率化するAIハードウェア/アクセラレーターでは、演算不要のノードを効率よく処理することが難しい。
 既存の並列プロセッサによる枝刈りモデル処理の課題。並列演算器では、ゼロの重みもゼロ以外の重みも全て演算されてしまう。つまり、ゼロを増やしても、トータルの演算時間を削減できず、枝刈りの効果が十分に得られない[クリックで拡大] 出所:ルネサス エレクトロニクス
既存の並列プロセッサによる枝刈りモデル処理の課題。並列演算器では、ゼロの重みもゼロ以外の重みも全て演算されてしまう。つまり、ゼロを増やしても、トータルの演算時間を削減できず、枝刈りの効果が十分に得られない[クリックで拡大] 出所:ルネサス エレクトロニクスルネサスが開発したDRP-AI3は、回路情報を動的に変更するDRPの柔軟性を生かし、演算不要のノードを高い効率で処理できるという。具体的には、重要な重みのみを抽出して圧縮する「フレキシブルN:M枝刈り手法」を採用した。圧縮することで、演算サイクル数を削減できる。さらに、DRP-AI3では、AIモデルの重み行列グループごとに圧縮率を自由に変えられる他、その圧縮率に応じて演算サイクル数も調整できる。これにより、演算サイクル数を最小で16分の1に、消費電力を最小で約8分の1以下に削減できるという。ルネサスのエンベッデッドプロセッシング第一事業部でシニアプリンシパルプロダクトエンジニアを務める野瀬浩一氏は、「高い枝刈り率と、高速な処理性能を両立できる」と強調する。

 枝刈りモデルの処理性能を、既存のアクセラレーターと比較したもの。左は一般的な並列プロセッサ。モデルの軽量化はできても、演算サイクル数を減らすことはできない。中央は、「隣接する2つの重みデータのうち、どちらか1つを選択して演算する」という枝刈り手法を適用したもの。「ただしこの手法は、構造的な限界により、演算量を最大でも2分の1にしか削減できない」(野瀬氏)[クリックで拡大] 出所:ルネサス エレクト
枝刈りモデルの処理性能を、既存のアクセラレーターと比較したもの。左は一般的な並列プロセッサ。モデルの軽量化はできても、演算サイクル数を減らすことはできない。中央は、「隣接する2つの重みデータのうち、どちらか1つを選択して演算する」という枝刈り手法を適用したもの。「ただしこの手法は、構造的な限界により、演算量を最大でも2分の1にしか削減できない」(野瀬氏)[クリックで拡大] 出所:ルネサス エレクトDRP-AI、DRP、CPUが協調動作
ルネサスは、主にロボティクス制御に向けて、DRPとDRP-AI3、CPUが協調動作するヘテロジニアスアーキテクチャも開発した。これら3つを組み合わせることで、「AI処理」「AIを使わないアルゴリズム処理」が混合していても、マルチスレッド化やパイプライン処理が可能になるとする。
協調ロボットでは、周辺環境の認識に加え、ロボットの行動判断や制御をリアルタイムに実行する組み込みシステムへの需要が高まっている。このようなシステムでは、周辺環境などの認識をAIで行う一方で、行動判断/制御には、AIを使わないアルゴリズム処理が行われている。
ルネサスが提案するヘテロジニアスアーキテクチャは、AI処理をDRP-AIで、AIを使わないアルゴリズム処理をDRPとCPUで実行することで、ロボットアプリケーションの高速化と低消費電力化を図るというもの。「ロボット制御では複数のアルゴリズムを組み合わせる必要がある。DRPは、1ミリ秒でアルゴリズムを切り替えられるので、ロボットアプリケーションとの相性がよい」(野瀬氏)。画像処理では、AIを使わない画像処理(AIの前後の処理)をDRPで実行することで、システム全体の処理時間を削減できるという。

ファンレスでAI処理が可能に
ルネサスは、DRP-AI3や、ヘテロジニアスアーキテクチャを実装したテストチップを14nmプロセスで作成。0.8Vの電源電圧で、23.9TOPS/Wの最大電力効率を達成した。主なAIモデルを動作したときの電力効率は10TOPS/Wだったという。「ファンやヒートシンクを使うことなく、AI処理を行えることを示した」(ルネサス)と強調する。
ロボットの周辺環境認識を広い視野で行う場合、100TOPSに近いピーク性能が求められる。だが、このような高性能なAI処理が行えるAIアクセラレーターは発熱も大きい。「ロボットに組み込む段階で、発熱が大きすぎてロボットに組み込めないことに気付くケースもある。ファンレスでAI処理をするには、10W以下で動作するAIアクセラレーターが必要になる」(野瀬氏)
 テストチップの概要[クリックで拡大] 出所:ルネサス エレクトロニクス
テストチップの概要[クリックで拡大] 出所:ルネサス エレクトロニクスビジョンAIと高速リアルタイム制御を「ファンなし」で実現
ルネサスは2024年2月29日に、DRP-AI3とヘテロジニアスアーキテクチャを適用したビジョンAI向けMPU「RZ/Vシリーズ」の新製品として、「RZ/V2H」を発売した。RZ/Vシリーズでは最もハイエンドとなる製品で、既に量産も開始している。
RZ/V2Hは、アプリケーション処理を担うLinux用に最大動作周波数が1.8GHzのArm Cortex-A55を4コア、リアルタイム処理を担うRTOS用には同800MHzのCortex-R8を2コア、サブCPUとしてCortex-M33を1コア搭載。ロボティクス制御に必要なビジョンAIと高速リアルタイム制御を1チップで実現できるという。


RZ/V2Hは、DRP-AI3により電力効率を従来の10倍に高めた他、10TOPS/Wの処理性能を実現している。既存のRZ/Vシリーズの中で、最も高速にAI推論を実行できる。例えば、ResNet50による画像分類ではエントリーレベルのRZ/V2Lに比べて14倍、YOLOv2による物体認識では同9倍の推論性能を達成した(いずれも枝刈りを適用していないモデルを使用)。枝刈りを使うと、ResNet50では45倍もの性能を実現できるという。

さらに、DRPを適用し、画像処理ライブラリであるOpenCVの処理を高速化するOpenCVアクセラレーターを開発。これもRZ/V2Hに搭載した。これにより、OpenCVの処理はCPUに比べて16倍高速化できる。
ルネサスは、RZ/V2Hを搭載した評価ボードと、NVIDIAのGPUボード(「Jetson Orin Nano」)を用いて人物を認識するデモを行い、ボードの発熱を比較するデモを行った。

 左=AI推論(人物認識)のデモ。左側がRZ/V2Hの評価ボードで、右側がGPUボード。推論性能は同等だった/右=ボードの発熱を比較している。GPUボードにはファンとヒートシンクが付いているにもかかわらず、チップのみのRZ/V2Hと同じくらいの温度ということが分かる。実際に触れてみても熱くなく、「温かい」と感じる温度だった[クリックで拡大]
左=AI推論(人物認識)のデモ。左側がRZ/V2Hの評価ボードで、右側がGPUボード。推論性能は同等だった/右=ボードの発熱を比較している。GPUボードにはファンとヒートシンクが付いているにもかかわらず、チップのみのRZ/V2Hと同じくらいの温度ということが分かる。実際に触れてみても熱くなく、「温かい」と感じる温度だった[クリックで拡大]
なお、RZ/V2Hの開発キットも既に提供中。さらに、Raspberri Pi(ラズパイ)のフォームファクターを踏襲し、RZ/V2Hを搭載したSBC(シングルボードコンピュータ)「Kaki Pi」(カキパイ)も発表した。AMR(自律走行搬送ロボット)やHSR(Human Support Robot)の開発向けのSBCで、ユリ電気商会から2024年4月後半にも販売を開始する予定になっている。

 「Kaki Pi」の外観。ロゴマークもかきの形をしていて、何だかかわいらしい。取材陣は「“かきぱい”? え、読み方はかきぴーじゃないんですか!?」と盛り上がっていた[クリックで拡大]
「Kaki Pi」の外観。ロゴマークもかきの形をしていて、何だかかわいらしい。取材陣は「“かきぱい”? え、読み方はかきぴーじゃないんですか!?」と盛り上がっていた[クリックで拡大]----------https://eetimes.itmedia.co.jp/ee/articles/2212/22/news130.htmlhttps://eetimes.itmedia.co.jp/ee/articles/2212/22/news130.htmlルネサス独自のDRP技術がベース低消費電力で高速な推論を実現する組み込みAIチップ
(1/2 ページ)
ルネサス エレクトロニクス(以下、ルネサス)は2022年12月8日、NEDOのプロジェクトにおいて、従来技術に比べて最大10倍の電力効率を実現したAI(人工知能)チップを開発したと発表した。
ルネサス エレクトロニクス(以下、ルネサス)は2022年12月8日、NEDO(新エネルギー・産業技術総合開発機構)が進める「高効率・高速処理を可能とするAIチップ・次世代コンピューティングの技術開発」プロジェクトにおいて、従来技術に比べて最大10倍の電力効率を実現したAI(人工知能)チップを開発したと発表した。
今回開発したAIチップは、ルネサス独自のDRP(動的再構成プロセッサ)をベースにしたもの。DRPは、チップ内の演算器の回路情報を処理内容に応じて動的に切り替えながら、必要な回路だけを動作させる技術である。ルネサスのIoT・インフラ事業本部 エンタープライズ・インフラ・ソリューション事業部で主幹技師を務める野瀬浩一氏は記者説明会で、「DRPは無駄のない動作を継続できるので、低消費電力かつ高速な処理が可能になる」と説明する。ルネサスはさらに、このDRPと積和演算ユニットを一体化し、AI処理性能を強化したAIアクセラレーター「DRP-AI」を開発している。DRP-AIを応用し、軽量化したAIモデルを効率的に処理できるAIアクセラレーターの開発に成功したのが、今回の成果になる。
AIモデルを軽量化する技術の中でも、今回は枝刈りに注目した。「一般的に、AIモデル内で認識精度に影響のない演算は、不規則に存在する。既存のAIアクセラレーターは、規則的に並んだ演算を並列処理することは得意だが、枝刈りのように、不規則に順番が飛ばされた演算は得意ではない。そのため、ハードウェアの並列性と枝刈りの不規則性に差があり、効率よく処理できないことが大きな課題になっていた」と野瀬氏は述べる。
今回開発したAIアクセラレーターは、DRP-AIが持つ高い柔軟性(動的に切り替えできるということ)を活用することで、きめ細かく枝刈りした場合、つまり枝刈り率が高い場合でも、効率よく演算をスキップできる。これにより、ある程度の認識精度に必要な演算に絞りながらも、ハードウェアの並列性を維持して処理することが可能になるとする。
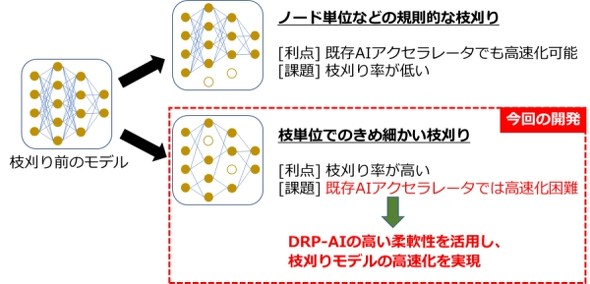
検証した結果、演算量を最大90%削減する枝刈り率のAIモデルにおいて、従来技術(現行のDRP-AI)に比べ最大で10倍の高速化を実現し、1W当たり最大で10TOPSの電力効率を達成した。野瀬氏は「これは、ファンレス動作が可能な10W以下の電力で、数TOPSを必要とする高度なAIのリアルタイム処理が可能になる値だ」と説明する。
認識精度の低下はわずか3%にとどまっている。「従来技術を使用したときとほぼ同等の精度が得られることを確認した。今回の開発により、大幅な高速化と低消費電力化、そして精度の維持を両立することができた」(野瀬氏)
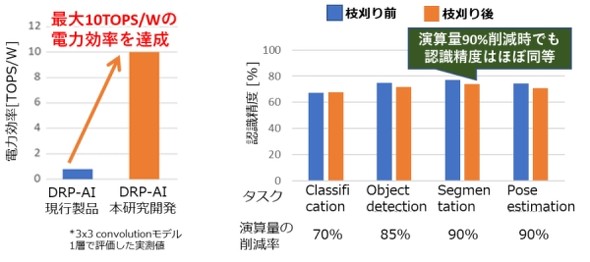 左は従来技術との電力効率の比較。右は、枝刈りによる演算量の削減率と認識精度の関係 出所:ルネサス エレクトロニクス
左は従来技術との電力効率の比較。右は、枝刈りによる演算量の削減率と認識精度の関係 出所:ルネサス エレクトロニクス周囲の環境に適応する「追加学習」も可能に
さらに、エンドポイント機器を使用環境に対し、自律的な対応ができる学習システムも構築した。AIを搭載した機器は、同じモデルで学習させても、機器の設置場所やセンサーのばらつきによって認識精度が変わってしまうという課題がある。野瀬氏は「例えばカメラの構造上の違いや、周辺の光の当たり方の違いといった要素で、認識精度を高いまま維持できる機器もあれば、低くなってしまう機器もある。こうしたばらつきが生じてしまうことが実用上の課題になっていた」と述べる。
そこで今回、エンドポイント機器でAIを実行しつつ、「追加学習」を用いることで、環境の変化に対応できる学習システムも構築。具体的には、精度が低くなってしまったAIモデルを、使用環境に合わせて最適化し、精度を復元させるという技術を開発して応用した。「AIの実行を止めずに、フレキシブルなDRPの特性を生かして追加学習ができることがポイントだ。これにより、追加学習の時間を別途確保したり、データを追加で収集したりといった手間がなくなり、運用が格段に容易になる」(野瀬氏)
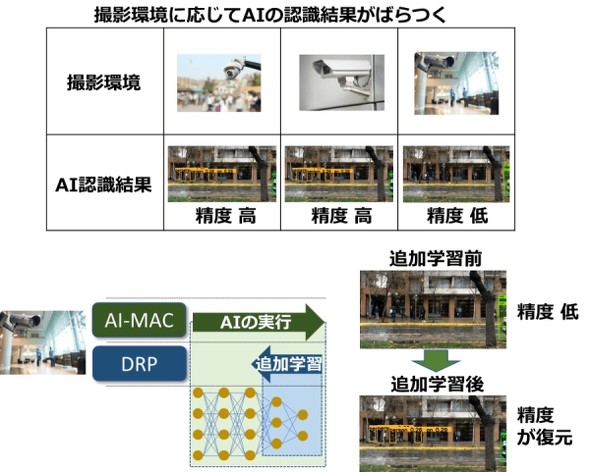
NEDOの「高効率・高速処理を可能とするAIチップ・次世代コンピューティングの技術開発」プロジェクトでは、ルネサスの他、東京工業大学、SOINN、三菱電機が連携して、高度なAI処理を低消費電力で実行できる、DRPベースの組み込みAIチップの実用化を目指している。今回の成果を基に、NEDOと各社は、同技術の詳細な評価と実証実験を進める予定だ。ルネサスは、今回の成果をいち早く実用化につなげるべく、IoT・インフラ事業向け製品への適用を計画しているとする。
NEDO IoT推進部の主任である岩佐匡浩氏は、「AIチップをIoT機器に組み込む際の課題の一つとして、AI処理を行うときの発熱(消費電力)があった。今回の成果により、幅広い機器へのAIチップの組み込みが期待される」と語った。









0 コメント:
コメントを投稿