https://enterprisezine.jp/article/detail/13727
2020年12月8日、企業のデータ活用の現状、そしてこれからの姿を明らかにする翔泳社のカンファレンスイベント「data tech 2020」がオンライン開催された。今回のテーマは「データドリブン・アップデート 真のデータドリブン経営の姿」。データ活用基盤およびデータマネージメントカテゴリーのセッションでは、クラウドデータ活用プラットフォームの提供で大きく注目されているSnowflakeが、「DATA CLOUD:Snowflakeが目指すデータコラボレーションプラットフォーム」と題し講演を行った。自社のデータをSnowflakeに格納することでデータドリブン経営につながるデータ活用ができるようになること、そして他組織ともデータ連携が実現できる画期的なアーキテクチャ「DATA CLOUD」について、その価値と事例について紹介した。

データは世界を映す鏡だが、データがばらばらだと上手く写せない
DATA CLOUDとは、組織を超えてデータコラボレーションすることであり、これができるようになると「年間で300兆円ほどの価値があるとも言われています」と言うのは、Snowflake シニアセールスエンジニアのKT氏だ。

社内にあるデータだけでは、真にデータドリブン経営を実現するには十分ではない。組織横断のデータが使えることで、より価値ある意思決定が迅速にできるようになる。
DATA CLOUDの詳細に触れる前に、世の中のデータ活用の現状が解説された。今、データは世界を映す鏡となっている。世界と言うのは、目の前にあり見えているものだけではない。何らかの情報を使い「間」を埋めていくことで、どんどん想像できる世界が拡がる。「データで目の前にないものも見えてくるのです」とKT氏。
今、COVID-19の様々な問題を解決しようと、人々が立ち向かっている。とはいえ多くの人の目の前に、感染して苦しんでいる人が存在するわけではない。データをもとに分析し、COVID-19の感染状況が世の中でどうなっているかを把握でき、そこから人々が対策に動き出すことになる。つまりデータを分析しCOVID-19の世界が見え、それによって新たな行動が起きるのだ。
COVID-19の世界を明らかにするために、世界中の様々な人がデータ分析のための地道な努力を続けている。しかしながらデータ分析には、大きな手間がかかっている。たとえば提供されるデータがPDF形式だったり、それがある日突然画像データになったりする。それらを分析できる形にして集めるには、大きな手間がかかるのだ。集めてきれいにするのに手間がかかれば、分析にはなかなか集中できない。
COVID-19の状況把握に限らず、データが分散しているとデータドリブンな意思決定にはつながらない。つまりデータは世界を映す鏡とはいえ、多くの場合データが上手く活用できておらず、「データ ≠ 世界」となっているとKT氏は指摘する。
最初からクラウドに最適化されたアーキテクチャで登場したSnowflake
データが分散し活用できていない課題を解決するために、Snowflakeは2012年に誕生した。ちょうどクラウドが普及し始め、クラウド上に第一世代のクラウドデータベースが登場した頃だ。この第一世代は、今までオンプレミスで運用してきたデータベースを「クラウドの無限のリソースで使えるようにしたものです」とKT氏。オンプレミスのデータベースをそのままクラウドにのせたようなものが多く、クラウドに最適化されていなかったと説明する。
対してSnowflakeは、最初からクラウドネイティブなアーキテクチャで生まれた。「クラウドのリソース、をいかに効率的に使えるかを考えるところから始まっています」とKT氏。その発想から生まれたクラウドに最適化されたアーキテクチャで、まずはクラウドデータウェアハウスとしてSnowflakeは2014年にサービスの一般提供を開始する。
その後データウェアハウスだけでなく、AIのためのデータベースなどとしても利用されるようになり、2019年にはあらゆるワークロードを支えるクラウドデータプラットフォームへと進化する。その後も自社のテクノロジーを革新させつつ時代のニーズに合わせることで、2020年には組織間でデータコラボレーションができるようにDATA CLOUDへとさらに進化した。

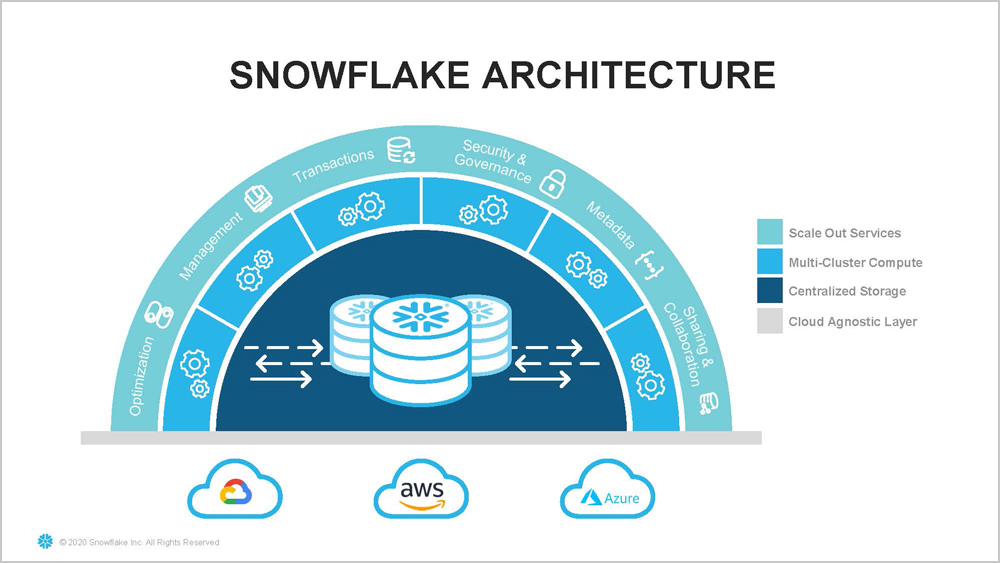
組織においてデータドリブンな意思決定が上手くいかない大きな原因が、データのサイロ化だ。データは今、様々なところで生まれる。人事システムがあればそこで人事に関する情報が生まれ、会計や顧客管理のシステムも同様だ。それぞれの場所でシステムの目的に応じデータは加工され、システムごとにサイロ化してしまう。この「データのサイロをなくすことが、Snowflakeのアーキテクチャの原点でもあります」とKT氏。
またデータをなるべく細かい単位で格納すれば、よりリアルに近い世界を映し出せる。そのため可能な限り漏らさず記録しようとすると、扱うデータは莫大になる。システムごとに生まれた莫大なデータを1ヵ所に集めるには、加工に手間がかかり、十分な処理性能も得られずデータを上手く扱えなくなる。結果データを分けて置いたり、目的ごとに別々に保存したりするのだ。
対してSnowflakeでは、データは1ヵ所のクラウドストレージに格納する。データを処理するためのコンピューターリソースは、必要に応じていくつでも準備できるようになっている。蓄積されたデータに対するワークロードは、たとえば大量データのロード、莫大なデータに対するアドホック検索、バッチ処理による集計など様々なものがある。これまでは様々なワークロードの処理の最大値を考え、ハードウェアなどのインフラ容量を購入しセットアップし利用してきた。
Snowflakeは、実行したいワークロードごとに必要なコンピュータリソースを割り当てる。たとえば「ETLのワークロードには、必要なリソースだけを割り当てます。それを秒単位で立ち上げ、本当に必要な分だけ利用します。課金も必要な分だけです」とKT氏。また1ヵ所のストレージに格納すれば、データに対するセキュリティやガバナンスの制御もそれだけに施せば良い。これもデータ管理側面では大きなメリットとなる。Snowflakeでは現状、構造化データはもちろん、半構造化データも扱える。さらに今後は、非構造化データにも積極的に対応する予定だ。

「Snowflakeではどんなに大量なデータでも対応できます。入れたいものはすべて入れられ、ストレージサイズの上限を気にする必要はありません。蓄積した大量なデータに高速にアクセスできすぐに答えを返せます」とKT氏。SnowflakeはAWS、Azure、Google Cloudにマルチクラウド対応しており、世界中のどのリージョンでも選ぶことができる。
Snowflakeでデータを共有し、未来を決める意思決定が可能となる
Snowflakeの1つのデータベースに入れることで「データは自分たちだけでなく、グループ企業間などとすぐに共有できます」とKT氏。共有のために、どこかにデータをコピーする必要はない。Snowflakeにデータがあれば、グループ会社だけでなく第三者の外部組織と共有するのも、公開されているオープンデータを共有するのも容易だ。「これはSnowflakeがクラウドネイティブの柔軟なアーキテクチャがあるからこそ、実現できるものです」と言う。
このSnowflakeのDATA CLOUDの取り組みは、未来の話ではない。たとえば英国の大手スーパーマーケットSainsbury's社の例では、事業会社間でばらばらだったデータをDATA CLOUDで共有し、6時間かかっていた検索が3秒で処理できるようになった。自社の在庫データ、ニールセン社のCOVID-19の経済的影響の情報、Ibotta社のモバイルアプリによる消費者の行動履歴、Weather Source社の天気の情報など、自社にない様々なデータを共有し、在庫を最適化し適切な意思決定ができるようになっているのだ。


SnowflakeではData Marketplaceを用意しており、ここから無償、有償でデータをすぐに共有できる。「COVID-19の感染状況に対する政府の意思決定でも、ここにあるデータが使われています」とKT氏。カリフォルニア州などでは、ここのデータを用い状況をリアルタイムに理解し、実際の感染対策のための意思決定に利用している。今後はデータドリブンの意思決定が、さらに増えていくとも言う。
Snowflakeには、既に世界に3,000社ほどのユーザーがある。それらの多くの企業がData Marketplaceにデータを置き、コラボレーションしながら未来を決める意思決定ができるようになる。今回のセッションでデータを共有する価値、さらにコラボレーションすることで意義ある意思決定ができることを理解して欲しいとKT氏。「皆さんのデータはものすごい資産です。でも今はまだ資源に過ぎず、どう保管するかと考えているとなかなか前には進めません。Snowflakeなら苦労せずにデータ活用ができるようになり、データを本当の資産に変えられます。さらにDATA CLOUDでデータ共有することで、世界中をデータドリブンにしていきたいです」と言う。

クラウドデータウェアハウスからクラウドデータプラットフォームとなり、さらにDATA CLOUDへと進化するSnowflake。この進化により企業のデータドリブン経営が加速する未来を、うかがい知ることができたセッションとなっていた。









0 コメント:
コメントを投稿