https://aon.co.jp
https://aon.tokyo
ーーー
JAPANESE.日本語。
https://jp.quora.com/MS%E3%81%AEACCESS%E3%81%A3%E3%81%A6%E4%B8%8A%E6%89%8B%E3%81%84%E3%81%93%E3%81%A8%E3%82%84%E3%82%8C%E3%81%B0%E3%82%81%E3%81%A1%E3%82%83%E3%81%8F%E3%81%A1%E3%82%83%E3%81%84%E3%81%84%E3%82%A2%E3%83%97%E3%83%AA%E4%BD%9C
ーーー
ENGLISH.
https://jp-quora-com.translate.goog/MS%E3%81%AEACCESS%E3%81%A3%E3%81%A6%E4%B8%8A%E6%89%8B%E3%81%84%E3%81%93%E3%81%A8%E3%82%84%E3%82%8C%E3%81%B0%E3%82%81%E3%81%A1%E3%82%83%E3%81%8F%E3%81%A1%E3%82%83%E3%81%84%E3%81%84%E3%82%A2%E3%83%97%E3%83%AA%E4%BD%9C?_x_tr_sl=ja&_x_tr_tl=en&_x_tr_hl=ja&_x_tr_pto=wapp
ーーー
Versionless APIという世界。
REST API & GraphQLの良い所取りのハイブリッドなWunderGraphのCloud版への適用の検討。
https://zenn.dev/kinzal/articles/74a761de1cc52d
https://zenn.dev/kinzal/articles/74a761de1cc52d
とりあえずAPI開発に関わる人たちはWunderGraphのManifestoを読んで欲しい。
とても良いことを言っていて、僕はこれを見て多用なクライアント、多用なマイクロサービスが生まれ、サービスを開発するために複数のAPIを実行しなければいけない時代における次世代のAPI管理のプラクティスだと感銘を受けました。
もし、同じような印象を受けたならよりHowに寄った話のUse Casesを読むこともおすすめします。こちらはちょっと「んん・・・?」みたいに思うことはありますが、全体としてはとても良いことを言われてます。
中でもVersionless APIについては素直にこれが欲しかったと叫びたくなるものです。
バージョンレス API は、API をバージョン管理しないという意味ではありません。 これは、クライアントを壊すことなく API を進化させ続けることができるということです。
しかし、最も重要なことは 、この機能により、 バージョン管理について考えなければならないという精神的負担がまったくなくなったことです。
過去 2 か月以内に API Gateway と通信したクライアントなど、サポートするクライアントを構成し、を 実行してから関数を実装します。wunderctl generate migration
移行テストスイートがグリーンになると、 クライアントを中断することなく、更新された API をデプロイできます。
API開発で後方互換性をなくなる変更を入れるときにネックになるのはクライアントの存在です。
この記事を読んでいる皆さまも同じように問題があることがわかっているから変更したい。が、クライアントに変更が波及し、変更するためのコストが大きく変更する決断が行えないという経験はありませんか?僕はよくあります。
また、モバイルクライアントでは古いアプリケーションが長期間に渡って動作するため、モバイルサポートをしているならどうしても変更に長期間かかります。
昨今の開発事情ではアジリティを最大化するために変更容易性を高めていくことが重要になってきています。
それなのに、サービスは分割され、多くのクライアントと合意してAPIの変更を行わなければいけないというアジリティを低下させる要因となってしまいます。
それがVersionless APIの世界ならなくなるなんて素晴らしい!!!!と、言いたいところですが、そんな上手い話は転がってる訳がないのですよ。
2022/12現時点でWunderGraphのCloud版はEarly Accessなので検証できず、GitHubにあるVersionless APIを実現する方法は実装されてないように見えます。(僕の調査が甘いだけでもしあったらごめんなさい。見つけたら検証したいのでやり方教えてください)
という訳でないなら仕方ないので自分で作るしかありません。いきなり作って失敗するのも嫌なので、まずは何が必要で、どういったトレードオフが発生するのかを考えていきます。
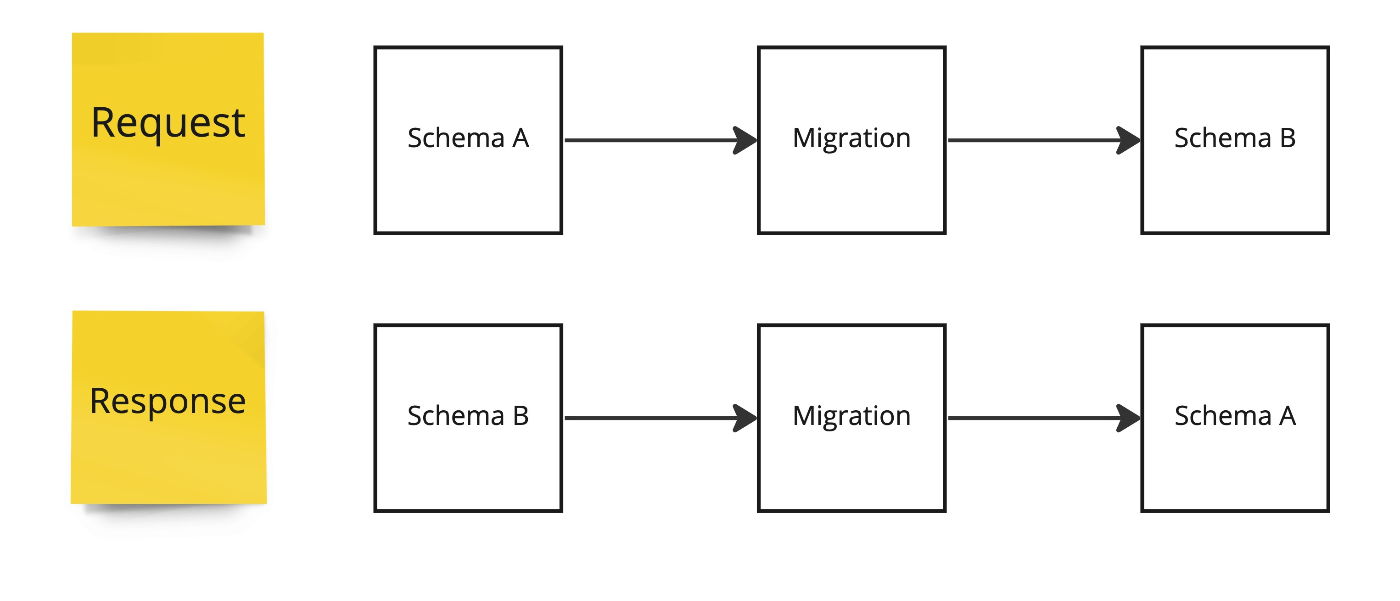
全体の構成

ユーザーのリクエストを軸に考えると下記のようなフローになります
- ユーザーがリクエストを行う
Routerがクエリに対応するSchemaを判別しルーティングを行う- 古いスキーマの
Schema Aに対応するリクエストならSchema AのResolverを呼び出す - 新しいスキーマの
Schema Bに対応するリクエストならSchema BのResolverを呼び出す
- 古いスキーマの
- 古いスキーマの
Schema Aの場合、Migrationを呼び出しSchema Bのリクエストに変換する Schema Bで解決を行い、Migrationに結果を返し、Schema Aのレスポンスに変換する
ざっくりとした形にはなりますが、こういった形であれば後方互換性を維持したVersionless APIを作ることができそうです。
それぞれの要素について詳細を見ていきます。
Router
Routerの役割はリクエストからスキーマを判別し、どこにルーティングするのか決定することになります。
では、このスキーマの判別というのはどのように行えば良いのでしょうか。
- 事前にリクエストとスキーマの紐付けを行う
- WunderGraphはおそらくこの方式。事前にSchemaとOperationを定義するのでできる
- リクエストにスキーマを特定する情報を付与する
- 例えばリクエストに対応するスキーマのハッシュをヘッダーに埋め込むなど
- リクエストを最新のスキーマから順にパースして成功するか判定する
それぞれトレードオフがあり、1に近づけば実行時に判定を高速に行えますが事前に行うためのフローを構築する必要があります。逆に3に近づけば事前準備が不要になる代わりに実行時にレイテンシが悪化するケースが起こりえます。
そういう意味では2がバランスよく、クライアント開発でスキーマバージョンは取得できるのでビルド時やデプロイ時にそのスキーマバージョンを埋め込む機能があれば実現できそうです。
Migration
Migrationは2種類あり、リクエストマイグレーションとレスポンスマイグレーションが考えられます。
function requestMigration(request: Request<SchamaA>): Request<SchemaB> {
// ...
}
function responseMigration(response: Response<SchemaB>): Response<SchemaA> {
// ...
}
ざっくりとしたコードにはなりますが、このような2つの関数の形でしょうか。
こう考えると何でもはマイグレーションはできないように見えてきますね。後方互換がなくマイグレーションできないケースについて考えてみましょう。
request
| スキーマ操作 | マイグレーション可 | 備考 |
|---|---|---|
| 追加 | × | Aになく、Bに必須要素が追加された場合は情報がないためマイグレーションできない |
| 更新 | △ | fieldA: TimeStampからfieldA: DateTimeなど元情報を使える変更はマイグレーション可能だが、fieldA: DateTimeがfieldA: Emailなど関係ない変更はマイグレーションできない |
| 削除 | ○ | 常にマイグレーション可能 |
response
| スキーマ操作 | マイグレーション可 | 備考 |
|---|---|---|
| 追加 | ○ | 常にマイグレーション可能 |
| 更新 | △ | fieldA: TimeStampからfieldA: DateTimeなど元情報を使える変更はマイグレーション可能だが、fieldA: DateTimeがfieldA: Emailなど関係ない変更はマイグレーションできない |
| 削除 | △ | Aになく、Bに必須要素が追加された場合は情報がないためマイグレーションできない。ただし分割などで別のスキーマに問い合わせで解決できる場合はマイグレーション可能 |
つまりマイグレーション元に情報がないケースは行えない形になります。
更新のケースはどちらもまずないとして、リクエストの追加は必須の入力値を増やすケース、レスポンスの削除は不要になった、フィールドに問題があり削除が必要などケースとしてはないとは言えません。(どちらも頻繁にあるケースではないですが)
大規模なスキーマの刷新はこの複合でできないスキーマ操作がなければ実現は可能そうです。
古いResolverを残す方法について
単純なマイグレーションではマイグレーションできないケースが存在するため、どんな状態でも後方互換性を維持する方法についても考えてみます。
単純に思いつくのは古いResolver実装を残す方法でしょうか。これなら確実に古いスキーマに対するリクエストを処理することができます。
pros
- 完全な互換性を実現できる
- マイグレーションの仕組みが不要になる
cons Resolverの実装が残り続けるため保守するコード量が増加する- もし、バックエンドのDBなどを変更するさいに古い
Resolverの実装の変更が必要など
- もし、バックエンドのDBなどを変更するさいに古い
ここは完全にトレードオフでMigrationする方法はこの裏返しになります。つまり焦点は古い実装をどれだけ保守するかですね。
感覚的にはクライアントの変更が遅いケースでは古いResolverが大量に残るため変更容易性が低下しやすそうです。逆に変更が早いならアグレッシブに古いResolverを削除できるので気にならないかもしれません。
もし僕が選ぶならクライアントの変更の速さはAPIの提供側のコントロール可能なものではないので、変更できないケースがあるconsを飲み込んでMigrationをする方法を選びそうです。もし、このAPIがBFFのようなものでコントロール可能なら古いResolverを残すかも。
その他の必要になりそうな要素
まず、トレースは必ず必要になります。
特に古いSchemaとMigration`(もしくはResolver`)を消す判断を行うためになければいけません。
次にトレースと繋いだスキーマの後方互換チェックを行うCIはあった方が安全そうです。もし過去Nヶ月以内にあったクライアントからのリクエストが動作しなくなるスキーマの変更は行えないようしないといけないです。
ここで一つ注意なのは後方互換のない変更を禁止する訳ではなく、クライアントが動作しなくなる変更を禁止しなければならないところですね。クライアント影響がないなら好きなだけ変更して良いです。
そういう意味ではトレースと繋ぐ必要はなくConsumer-Driven Contracts testingがあれば十分かもしれません。とか思ったけど、最新のクライアントだけをサポートすれば良い訳ではないのでやはりトレースと繋ぐ方が良さそうですね。
総括
こう考えていくとVersionless APIはやれそうな雰囲気はありますよね。
WunderGraphはGraphQLベースで僕も用語としてGraphQLに引きずられていますが、RESTful APIでも適用できそうな雰囲気があります。
おそらく焦点としてはどのようにしてMigrationを実装するのか、それの安全性をどう担保するのかといったあたりでしょうか。本当はWunderGraphでそれを検証して試したかったのに実装を見つけきれなかったせいで・・・。
道としてありそうなので時間を見つけて実装に落としてみたいですね。
おまけ
WunderGraphで遊んでみた感じを軽く書くと、思想や実現したい体験はよくわかるけどまだ早いって感じです。
ドキュメントを見てSupport!と言いつつ中を見たら対応中だったり、計画で止まっていたことから察しはしてました。
でも
。゚(゚இωஇ゚)゚。 < 罠でもいいんだっ!!
と触らずにはいれなかった魅力がWunderGraphには詰まっていますね。もし、今時点で利用をするならWunderGraphにコミットして一緒にAPIを育てていくぐらいの気持ちで進めると幸せになれるかもしれません。
Discussion
余談だけど、これってAPIだけではなくKinesis/Kafkaなどで行われるStreamingなんかでも大事な考え方になりそう。
Streamingの場合はProducerがイベントを流して、Consumerがそれを受け取って処理するだけでなのでVersionlessにする仕組みを入れる方法はない。なのでそこの関係性から変える必要があり、例えばGraphQL SubscriptionのようなConsumerが何を必要としているのか、ConsumerからProducerに伝えれる状態にできるとVersionless Streamingのような世界観が描けるかもなぁと妄想してます。
Kinesis/Kafkaなどで行われるStreamingなんかでも大事な考え方になりそう。
これらの event streaming platform では、schema evolution という呼ばれ方で、schema registory をつかって解決するアプローチが多そうですね。
- Validate, evolve, and control schemas in Amazon MSK and Amazon Kinesis Data Streams with AWS Glue Schema Registry
- Schema Evolution and Compatibility
あと、データ自体のシリアライゼーションフォーマットが、その機能を持っていることもあり、それを利用するのも多そうです。
Migration の項で考察されている、Migration 用の層を挟むアプローチは、schema registory を利用するアプローチに近いものがありそうですね。
情報ありがとうございます!
1つ僕が不勉強でよくわかっていないのですが、Schema Registry/Schema EvolutionはVersionless APIのように後方互換性のない変更を吸収するのではなく、ガードとして後方互換性ない変更を入れないための取り組みという認識であっていますか?
それともSchema Registryでそういった後方互換性のない変更を吸収できる仕組みがあったりするのでしょうか?
いえ、基本的には互換性のない変更は対応できないはずです。
たとえば、ConfluentPlatform の schema registory では、互換性レベルに応じて、Schema field の変更などのできることが変わるようですが、「先に変更が必要なロール」ができる形のようです。(Consumer から変更が必要というような。)
API においても、Schema A を構築するための情報が Schema B にない場合は、同じような形になると思いますが、例えば「互換性を崩さないためにそのような場合にはデフォルト値で埋める」みたいなことが、schema registory などでできるかは不明です。
ありがとうございます。理解が追いつきました。
Versionless API的なアプローチの場合とSchema Evolution的なアプローチの場合でクライアントに影響を与えないケースに差が出るのか洗ってみたいですね。Migrationレイヤーが入る分Versionless API的アプローチの方が懐が広そうですが、その広さは本当に必要なのかみたいなのはありそうだなと思い始めてきました。

幾つか理由が考えられます。
1. 拡張性:データサイズには限界があるだろう。おそらくMSとしてはExcelで扱うには不満がある程度には大きなデータを対象にしてる。しかし巨大なデータサイズには対応しそうにない。MS Accessのサーバーを複数台へスケールアウトするのって、ちょっと想像できない。
2. 継続性:Officeファミリーの一部は新版からなくなるモノが多い。継続してくれるか不安。
3. 互換性:新版が出た場合、以前の物と互換性があるか不安。
4. 情報漏洩:セキュリティに不安がある。
.
わたし的には、1レコードのアクセスごとにロックされず、前後の数レコードまとめてロックされるのがいや(RecordLocks プロパティで、2人のユーザーが同じ1つのレコードを同時に編集しようとした時の動作の事ではない)。アプリの設計で、異なるレコードへの同時アクセスの動作が保証されてないとか、例外処理で悩みたくない。例えば、1000番目のレコードと1001番目のレコードを比較してその結果で更新して書き戻すプログラムは書けるが、動作させると(それらは同じ記憶領域の1つのブロックだから)デッドロックになって止まる…とか。
そういうバカみたいな制約から解放されるなら、無料のPostgreSQLを選ぶ。
ちなみに……やたらプロパティとメソッドの呪文がダラダラ長くなる悪癖を持っていても、VBAはロジックとして分かり易いからそれは(わたし的には)問題ない。

Ver1.2がVer1.0のデータを読めなかったのでAccessは捨てました。

・accessはそもそも有料である。
⇒無料でイケてるビュワー付きのデータベースが多数ある。
・access単独でシステム構築がデキる、お手軽お気軽開発環境がウリだったのに、システムがWEBへ移行していて、access単独でWEBシステムが構築できない。
⇒CMSやローコード/ノーコードツールがその任を受け継いでいる。≒accessが再度入り込む余地が無い。
※accessはスタンド・アローン・ツールなんですよね。他との連携が C/S 以外では殆ど考慮デキていない。
と、云った処ではないかと。


補足は回答欄だったのですね。質問のコメント欄というのがありまして、そこに何も書かれていなかったので少し迷いました。
Araki Yuta さんの回答を読んだ上で回答してみます。
回答になったかどうかわかりませんし、井の中の蛙かどうかもわかりませんが、たぶんあまり見えにくい仕組みが中にあるかなと思い書いてみました。少し長文になってしまいました。
お役にたてば幸いです。
私は、フリーランスになってから.NET系で10年弱くらい、VBAのフルタイムの仕事を2年程したり、今は、JavaScript/TypeScriptで5年以上仕事しています。
VBAの求人件数が少ないのは、
- VBAの将来性がない
- 誰でもある程度デキる、ために、高単価な金額の仕事がない
- 誰でもある程度デキる、ために、外注することが少ない
ということになるかと思います。
VBAの将来性のなさはMicrosoftの戦略上の大きなミスだとは思います。まあ、そういう大きなミスをしてもMSは揺るがないくらいすごい会社さんなのですが、おかげで、SpreadSheetのGAS = GoogleAppScripts = JavaScriptにシェアは奪われました。
やるなら、GASの方を学んだほうがいいでしょう。(私もそうしています。)
将来性がないのと、高単価な仕事がないことによって、個人や開発の会社はVBAの仕事は基本敬遠します。なので、仕事を取らないし、取らないから更に下請けに出す、ということにもなりません。
VBAでできそうな仕事があったとしても、VBAはやめて他言語でやりましょうよ。となります。
また、低単価ですら求人件数が少ないのは、時間かければ社内人材でなんとかなるから新たに求人されるほどではない、ってところです。
ExcelVBAで2年近くフルタイムの仕事をしていた関係で、VBAにはめっぽう強いわたくしなのですが、そういうことがわかっているので、VBAスキルは全部捨てて、今後VBA仕事はたぶんしないと思います。
ソースコードを入出力するためのツール
GitHub - standard-software/ExcelInOut
VBAの標準ライブラリ的機能群
GitHub - standard-software/st_vba
ExcelVBAでExcel使っているとわからなくなるようなアプリ開発フレームワーク
ExcelMakeAppFramework/Readme_jp.txt at master · standard-software/ExcelMakeAppFramework
そのスクリーンショット
https://www.facebook.com/notes/325789828519721/
こんなのを作ってきましたが、残念ですが、これも将来のスキルアップにつながる段階だったのでしょう。
ExcelとVBAの組み合わせで成し遂げられる効果は非常に大きいので、便利ツールとしては最高でした。
高度なスキルが不要でこんな素晴らしい結果を出せるツールなので私も将来性があるかなと思っていろいろ作ってみたのですが、こんなスキル、業界じゃあ評価されないんすよ。評価されないってことは、腕によって稼ぐ、自分のようなものにとっては残念なことなんです。
「なんとかやってよー」と言われて、プログラマー未満の人がなんとかしてしまう、という状況があり、求人までには至らなかったり、
あるいは、プログラマーなら誰でもできるくらいの仕事だったりするので、経験年数が少ない人でも大丈夫だろうとなり、初心者プログラマーがすぐに仕事に応募して決まってしまうので、求人件数が増えることはなく、すぐに決まってその求人はなくなってしまう、というところがあるでしょうね。
プログラマーに対する、需要と供給の関係性でいうと、VBAの仕事は需要は多いかもしれませんが、十分に供給が多いので、求人としては増えていないというところです。
個人的にはVBAからさっさと足を洗ったほうが幸せになると思います。
Excelファイルから取り出して、Pythonで加工して、Excelとして吐き出す、みたいな開発スタイルができるようにライブラリもそろっていますし、CSVとPythonだけで加工してもありかもしれません。
そうすると、Pythonのスキルが身についていい感じになります。
他にも、
最近、自分はお友達の経営者の方のためにSpreadSheetで管理されている商品マスターなどを、いろいろ加工するものをGASで作成したりしています。GASも最高に便利だとはいいにくいのですが、JavaScriptは詳しいのと、GAS特有のことも学べるのでいい感じです。
将来的にSpreadSheetで作られるシステムはExcelを超えて広く普及すると予想しますので、このスキルもそれなりに役に立つでしょう。
なるべくお早めに、Pythonか、GASに移行できるなら、そちらにいったほうがよりよい気がします。
こんな感じです。










0 コメント:
コメントを投稿